
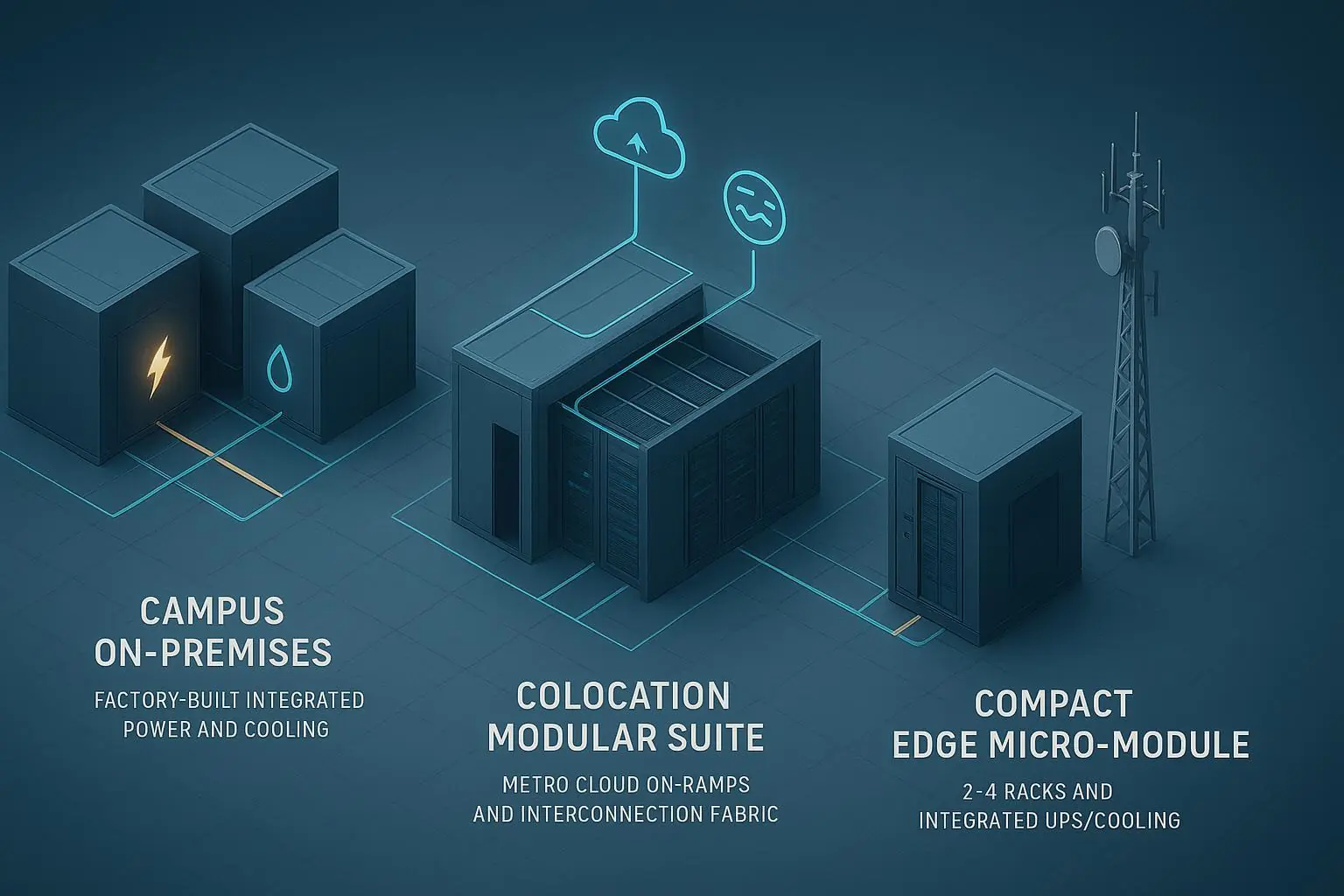
If you’re standardizing a hybrid estate across on‑prem, colocation, and edge, the hardest choice often isn’t the cloud. It’s the physical pattern you replicate. This guide compares three modular options using a baseline pod of 10–15 racks at 15–30 kW per rack, with an assumed factory‑integrated 0.5–1 MW power+cooling block as the default scope split.
Energy efficiency and heat density rule the decision. Most teams can cool 15–30 kW/rack with optimized air, but AI/HPC nodes push you toward rear‑door heat exchangers (RDHx) and direct liquid cooling (DLC) to sustain 60–100 kW/rack without runaway PUE. We’ll show where each modular data center architecture shines and where it struggles—and how to phase upgrades without dead‑ends.
Key takeaways
Factory‑built on‑prem blocks win for fast, repeatable campus growth in 0.5–1 MW steps and predictable efficiency; they’re the cleanest path to DLC‑ready pods when you control the plant.
Colocation modular suites are best when you need in‑region compliance and rich interconnection (low‑latency cloud on‑ramps, IXs) more than you need custom plant control.
Edge micro‑modules right‑size 2–4 racks for constrained sites (<10 kW/rack typical) but don’t scale well for dense AI clusters; treat them as spoke capacity, not your core.
Density path: ~15–30 kW/rack (air) → 30–50 kW/rack (RDHx) → 60–100 kW/rack (DLC with CDU/manifolds). Validate vendor datasheets before finalizing.
PUE planning: Modern designs often target ≤1.4–1.5; warm‑water DLC at high loads can approach ~1.1–1.2 in favorable conditions, per efficiency guidance and modeling assumptions.
Quick verdict by scenario
Scenario | On‑prem factory modular blocks | Colocation modular suites/pods | Edge micro‑modules |
|---|---|---|---|
Rapid campus expansion (0.5–1 MW steps) | Strong: block‑level repeatability and factory FAT reduce field risk | Moderate: depends on provider’s block options and fit‑out windows | Weak: not intended for campus‑scale growth |
AI/HPC 60–100 kW/rack | Strong if DLC‑ready (CDU/manifolds) | Strong in specialized high‑density suites (availability varies) | Weak: thermal/power limits |
High‑compliance region (Tier III target) | Strong if engineered and certified | Strong: many facilities hold certifications and audit processes | Limited: not typically certified to higher tiers |
Low‑latency multi‑cloud on‑ramp | Moderate: depends on metro/campus peering | Strong: native cloud on‑ramps and rich interconnection | Weak: relies on WAN backhaul |
Constrained/remote sites (<10 kW/rack) | Over‑provisioned | Over‑provisioned | Strong: purpose‑built 2–4 racks |
What “modular data center architecture” means for a 10–15‑rack pod
Our baseline pod is 10–15 racks at 15–30 kW/rack. A modular data center architecture in this context means you replicate a standard unit with:
Interconnects pre‑defined: power distribution and protection (UPS/genset topology), liquid or chilled‑water tie‑ins for RDHx/DLC, and a spine‑leaf network fabric pre‑cabled for 400G/800G evolution.
Factory/site scope split: power and cooling plants are factory‑integrated into a 0.5–1 MW block, FAT‑tested, then connected on site. This minimizes field variance and accelerates commissioning.
Expansion granularity: add capacity in predictable increments (another 10–15‑rack pod, another 0.5–1 MW plant block) with minimal disruption.
When you standardize this way across regions, you cut design risk, enable faster delivery, and keep global PUE/TCO within a tighter band. That’s the whole point of choosing a modular pattern rather than re‑inventing projects city by city.
Side‑by‑side comparison of modular options
The rows emphasized in bold are typically the most decision‑relevant for I&O leaders prioritizing efficiency and heat density.
Dimension | On‑prem factory modular blocks | Colocation modular suites/pods | Edge micro‑modules | Site‑built baseline |
|---|---|---|---|---|
Best for (scenario) | Campus growth with predictable 0.5–1 MW steps | In‑region compliance and rich metro interconnect | Constrained sites with 1–4 cabinets | Large bespoke projects with long horizons |
Pod size & rack density | 10–15 racks @ 15–30 kW/rack baseline; headroom via RDHx/DLC | Similar; density depends on provider’s options | 2–4 racks, typically <10 kW/rack | Any, but long design cycles |
Cooling strategy & DLC readiness | Air→RDHx→DLC with CDU/manifolds under your control | Air/RDHx common; DLC available in select suites | Integrated DX/in‑row; DLC uncommon | Depends entirely on project MEP |
Typical PUE range (design → measured) | ≤1.4–1.5 targets; DLC at high loads can approach ~1.1–1.2 with favorable climate | Similar targets; economies at campus colo scale | Highly load/climate sensitive | Ranges widely by design and climate |
Deployment speed (design‑freeze → lights‑on) | Accelerated by factory FAT; verify vendor timelines (weeks vary) | Fit‑out often faster than greenfield; schedule subject to landlord windows | Short install at site; permitting still applies | Longest path: full design, bid, build |
Factory vs site scope & FAT | Factory‑integrated 0.5–1 MW power+cooling; site tie‑ins | Provider integrates core plant; tenant fit‑out varies | Integrated UPS/cooling in enclosure | All site‑built with traditional QA |
Electrical architecture & redundancy | N/N+1/2N options per block; align to Tier goals | Varies by facility; can meet Tier targets | Small UPS (kVA range), limited redundancy | Any topology possible (time/cost) |
Expansion granularity & disruption | Add 0.5–1 MW blocks and pods; low disruption | Add suites/pods per lease and provider schedule | Add another micro‑module; limited aggregate scale | Project‑by‑project; higher disruption |
Network fabric readiness (400G/800G) | Pre‑cable spine‑leaf; plan optics for upgrades | Strong metro fabrics; native cloud on‑ramps | Limited fabric scale; backhaul to core | Flexible, but upgrades are slow |
Compliance & certifications | Engineering/certification under your control | Many sites carry Uptime/TIA/EN certifications | Usually not certified to higher tiers | Achievable; requires full program |
CapEx/OpEx notes (2026) | CapEx on campus; efficient at scale | OpEx lease; interconnect costs vary | Lower entry cost; higher $/kW at scale | Highest NRE; can optimize at very large scale |
Operability & serviceability | Standardized DCIM, spare strategy; good MTTR potential | Shared services; change windows subject to site policy | Simple but manual operations | Custom O&M burden |
References for select rows: efficiency targets and definitions per the United Nations U4E guidance on data center efficiency (2025), cited as “PUE” context, and a 2024 energy modeling assumption that many new designs plan around PUE ≈1.2 under favorable conditions. See the United Nations Environment Programme’s guidance in the Data Centers document (2025) at the Climate and Clean Air Coalition website: efficiency and PUE guidance, and the 2024 E3 white paper that models data‑center load growth using PUE 1.2 as a planning assumption: Load Growth Is Here to Stay (2024).
For interconnection, colocations in rich metros offer native cloud on‑ramps and software‑defined interconnect, as documented by Equinix in 2024–2025 materials: what a cloud on‑ramp provides and Fabric feature releases. For pod networking, spine‑leaf designs with 400G/800G upgrade paths are well described in Cisco’s 2024 white paper on massively scalable fabrics: Cisco Nexus 9000 fabric guidance (2024).
Compliance mapping relies on public explainers of TIA‑942‑C changes and Tier concepts; see EPI’s overview of the 2024 update: TIA‑942‑C release summary.
Link density note: Links above are primary sources intended to be timeless references; verify vendor‑specific capacities and certifications with current datasheets.
Scenario picks and how to decide
Rapid campus expansion with predictable 0.5–1 MW steps Choose factory‑built on‑prem modular blocks. You get standardized, FAT‑tested power and cooling with repeatable tie‑ins. Lead times vary by vendor and region, so lock timelines during procurement.
AI/HPC pod at 60–100 kW/rack If you need this density now, prioritize DLC‑ready architectures. On‑prem blocks give you plant control (CDU/manifolds, water quality, heat reuse). Some colo providers offer dedicated high‑density suites; confirm availability and service model.
High‑compliance region with Tier III target Either can work. Colocation modular suites often come with existing certifications and audit processes in‑region. If you require custom security controls or unique redundancy topologies, an engineered on‑prem block may be preferable.
Bandwidth‑intensive hybrid with cloud on‑ramp needs Colocation in rich metros has the edge thanks to native on‑ramps and interconnection ecosystems that shrink latency and tame egress costs. On‑prem can still work when located near carrier hotels and peering points.
Constrained remote sites (<10 kW/rack) Edge micro‑modules are purpose‑built here. Treat them as spokes feeding analytics or caching workloads, with backhaul to a core campus or colo hub for heavy compute.
Decision aids you can apply today
Density‑first decision tree (baseline: 10–15 racks)
At 15–30 kW/rack: Air remains viable with tight airflow management and aisle containment. Prepare RDHx tie‑ins if growth is likely.
At >30 kW/rack: Move to RDHx or hybrid air+liquid. Validate rear‑door capacity and water temperatures/delta‑T.
At 60–100 kW/rack: Plan DLC with CDU and row/pod manifolds; design for maintainability and isolation. Confirm facility supply temps and water quality program.
Brownfield migration checklist (5 phases)
Assess: inventory current rack densities, power paths, cooling capacities, and network constraints.
Pilot pod: deploy one 10–15‑rack pod to validate thermal/network assumptions and DCIM telemetry.
Factory FAT: insist on witnessed FAT for the 0.5–1 MW power+cooling block; document acceptance criteria.
Site integration: pre‑plan tie‑ins (power, liquid, network) with change windows; dry‑run SAT scripts.
Scale‑out: clone BOM and as‑built docs; capture measured PUE and MTTR to refine the template.
Pricing and TCO: how to compare like for like
Public numbers vary by region and vendor, and they shift with energy prices. As of 2026‑03‑05 (subject to change), here’s a practical way to estimate:
TCO model (simplified): TCO(5y) ≈ CapEx + Σ(Annual Energy Cost) + Lease/Service Fees + O&M
Key inputs you control:
Racks per pod (10–15), kW/rack (15–30 baseline), PUE (use scenario‑specific targets), regional energy price, network backhaul/interconnect costs, and staffing.
What to compare across options:
Scope in the price: Does it include UPS/genset, switchgear, chillers/CDU, containment, installation, SAT? For colo, isolate the OpEx lease and interconnection charges.
Expansion cadence: Are you buying 0.5–1 MW blocks, suites of fixed size, or individual micro‑modules? How does this align with demand uncertainty?
Efficiency trajectory: Can you improve PUE over time (e.g., warm‑water DLC, heat reuse) without stranded assets?
Pro tip: Build a sensitivity table for energy price ±30% and PUE ±0.1. Small deltas compound over five years—and can outweigh headline CapEx.
FAQ (snippet‑style answers)
Which modular data center architecture is best for 15–30 kW/rack pods? For most hybrid estates, factory‑built on‑prem blocks are the most repeatable at this band, delivering predictable PUE and clean 0.5–1 MW expansion. Colocation suites are close when interconnection or compliance is the dominant constraint.
How long does a 0.5–1 MW factory modular block take from design‑freeze to lights‑on? Vendors cite accelerated timelines due to factory FAT and reduced field work, but week‑level ranges vary by region and scope. Validate a full plan (design, FAT, shipping, site works, SAT) in contract.
What cooling strategy supports scaling from 15–30 to 60–100 kW per rack? Typical path: optimized air at 15–30 → RDHx to push past ~30–50 → DLC with CDUs and manifolds for 60–100+. Confirm water temperatures, delta‑T, and service isolation in design.
Should I choose colocation or on‑prem factory blocks for compliance and cloud on‑ramps? If you need immediate in‑region certifications and native cloud on‑ramps, colocation modular suites have the edge. If you need bespoke controls or plant‑level efficiency levers, on‑prem blocks are stronger.
How do I estimate TCO for a modular pod vs colocation? Use a 5‑year model with CapEx (or lease), energy cost via IT load×PUE×price, interconnect/backhaul, and O&M. Compare scope apples‑to‑apples and run ±30% energy price and ±0.1 PUE sensitivities.
Final guidance
There’s no universal winner. The right modular data center architecture depends on your density band, interconnection needs, compliance posture, and how fast you must scale. Start with the 10–15‑rack, 15–30 kW/rack pod, decide your air→RDHx→DLC path, and lock a factory/site scope split that you can stamp across regions. Then, double‑check vendor datasheets and certifications before you sign—because the details you validate now prevent surprises later.








