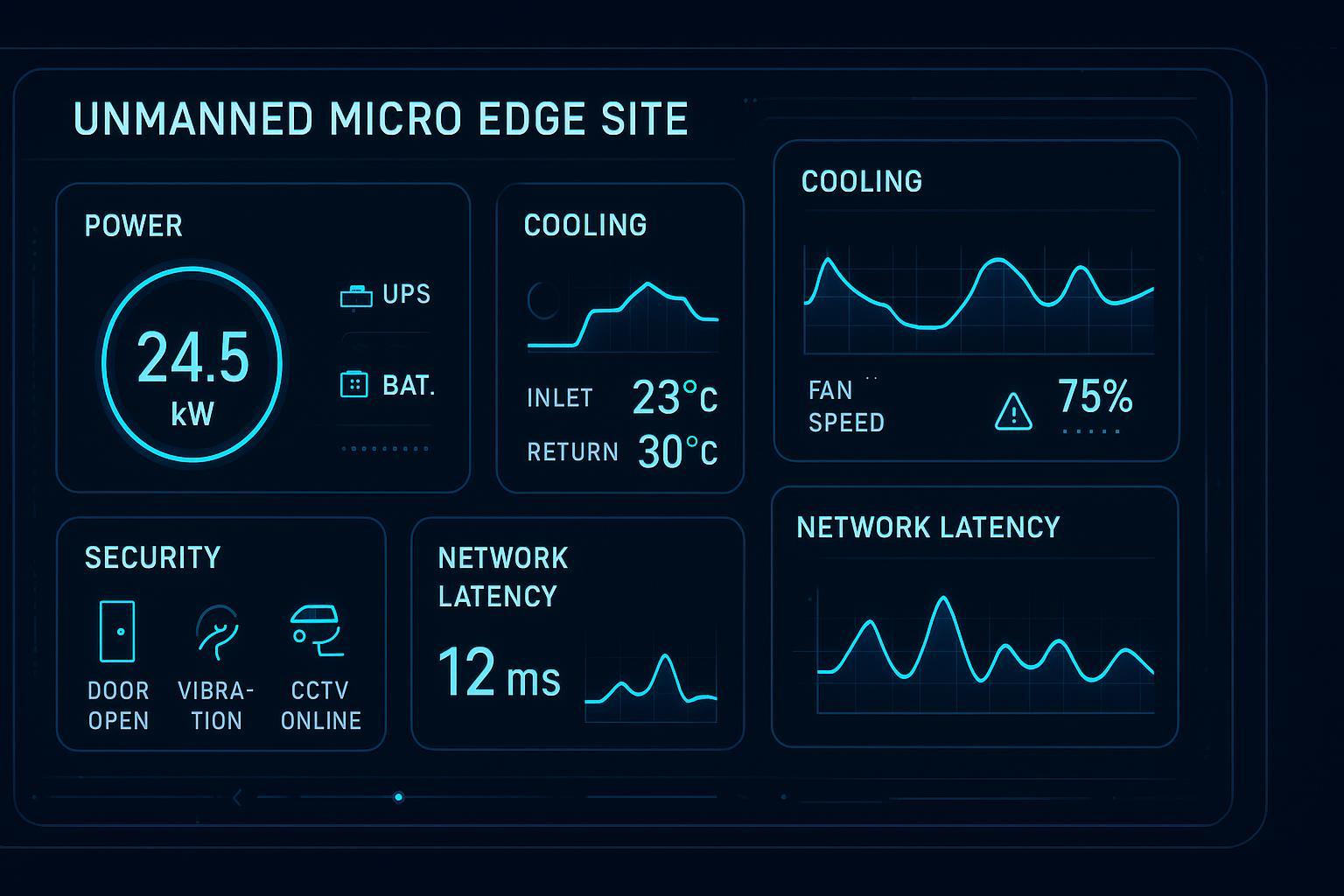
Edge and distributed rollouts have a different failure mode than large greenfield campuses: you can’t afford for every site to become a one-off construction project.
This comparison is written for teams that need a procurement-ready way to answer two questions:
How fast can we get to first IT load?
What has to be true for the faster path to actually produce faster ROI?
Key Takeaway: In edge programs, “speed” is mostly about parallel work + predictable integration, while ROI depends on what you include in TCO (and whether you price schedule risk explicitly).
Table of Contents
ToggleModular data center vs stick-built at a glance
Decision lens | Modular / prefabricated delivery | Stick-built (traditional on-site build) | What to verify before you believe any claim |
|---|---|---|---|
Speed to first IT load | Often faster because factory scope can run in parallel with site prep | Often slower because most scope is sequential and site-dependent | Utility power timeline, permitting triggers, long-lead equipment, commissioning gates |
CAPEX shape | More “packaged” scope; tends to be clearer at bid stage | More scope lives in site trades; variability is higher | What’s included/excluded (power chain, cooling, controls, security, civil works) |
OPEX shape | Can be favorable if right-sized and efficiently operated | Can be favorable at scale if optimized and heavily utilized | Partial-load efficiency, maintenance model, monitoring maturity |
Upgrade paths | Designed for repeatable expansion, but interface planning matters | Highly customizable, but expansions can be disruptive | What “upgrade” means: capacity, density, or both? |
Reliability | Standardization can reduce integration errors; module isolation can help maintainability | Custom design can be robust, but quality depends on site execution and change control | Evidence: redundancy diagrams, FAT/SAT/IST reports, spares plan, monitoring integrations |
Best fit | Distributed sites, repeatable designs, constrained build windows | Highly customized facilities, very large scale, unusual site constraints | Your portfolio reality: how many sites, how fast, how standardized |
Definitions (so we’re comparing the same thing)
Modular / prefabricated data center in this article means a solution where significant portions of the facility scope (typical examples include power, cooling, containment/enclosure, monitoring, and pre-terminated interconnects) are built and tested off-site, then installed on-site with a shorter integration window.
Stick-built means the facility is assembled largely on-site using conventional construction sequencing: civil works → structure → MEP installation → controls integration → commissioning.
The important nuance: both models still depend on site readiness (power, network, permits). Modular changes where work happens and how predictable integration can be.
Speed to service: what modular changes (and what it doesn’t)
A practical way to think about “prefabricated data center deployment time” is to separate parallelizable work from non-parallelizable constraints.
What modular can compress
On-site assembly time
More scope is completed in controlled factory conditions.
Less work happens in weather, labor, and access-window constraints.
Integration rework
A higher fraction of wiring, piping, labeling, and controls can be completed before the site window starts.
Commissioning risk (when done properly)
Factory and site testing don’t eliminate commissioning—but they can shift defect discovery earlier.
Commissioning vocabulary is inconsistent across vendors, so it helps to anchor on common gates. For an accessible overview of commissioning stages (including where FAT typically sits), see DataX Connect’s overview of the 5 data centre commissioning levels.
What modular usually does not solve
Utility interconnect timelines (approvals, transformer availability, upstream capacity)
Permitting triggers (zoning, fire marshal reviews, environmental or noise limits)
Network/carrier readiness (especially in remote sites)
Long-lead equipment constraints (if your program needs custom gear, you may still wait)
If those are your bottlenecks, a modular delivery model can still help—but the “faster” claim should be framed as: less on-site integration time, more schedule certainty once prerequisites are met, not “instant go-live.”
TCO model: what to include so ROI is comparable
If you’re building a worksheet, label it clearly as a modular vs traditional data center TCO comparison so stakeholders don’t mix scopes across options.
Most modular-vs-stick-built comparisons go wrong because they compare unlike-for-like scopes.
Use a simple rule: if it can change based on the delivery model, it should be inside the TCO boundary.
A practical TCO boundary for edge/distributed sites
Cost bucket | Include? | Notes for apples-to-apples comparison |
|---|---|---|
Site prep & civil works | Yes | Often similar (pads, trenches), but sequencing differs |
Electrical power chain | Yes | Utility service, switchgear, UPS (if in scope), distribution |
Cooling | Yes | DX, in-row, rear-door, liquid-ready interfaces—define architecture assumptions |
Controls & monitoring | Yes | BMS/DCIM integration scope matters for MTTR |
Security & access control | Usually | Often mandatory at edge/unmanned sites |
Installation labor & craning | Yes | One of the biggest differences in distributed sites |
Commissioning & testing | Yes | Separate factory testing vs site acceptance vs integrated testing |
Energy (PUE-driven) | Yes | Model as scenarios; don’t claim a universal PUE |
Maintenance & spares | Yes | Include response model assumptions (on-site vs regional) |
Financing / interest during construction | Yes | Time-to-service changes interest during construction |
Cost of delay (schedule slip) | Recommended | Especially relevant when edge sites unlock revenue or avoid downtime |
For the general economic logic behind prefabrication cost drivers (design reuse, standardized building blocks), it helps to separate what’s driven by design reuse and factory integration versus what’s driven by site-specific constraints (permits, utility timelines, labor, and access windows).
The minimal math (so payback isn’t hand-wavy)
You can keep the ROI math simple and still be rigorous.
Annual net benefit = (avoided downtime + incremental revenue + avoided opex + avoided risk cost) − (incremental opex)
Payback (years) = incremental CAPEX ÷ annual net benefit
Where “incremental” means: difference between modular and stick-built under the same capacity and SLA target.
Worked example: payback windows for a distributed edge rollout
In practice, modular data center ROI is usually driven by (1) time-to-service value, (2) right-sizing, and (3) reduced integration rework—so the model below keeps those levers explicit.
This is an illustrative model to show how to calculate payback—not a claim that every program will hit these numbers.
Assumptions (explicit on purpose)
One edge site delivered at a time.
Business value starts when the site reaches first IT load.
We treat “speed advantage” as months of earlier service.
We include a cost of delay (lost revenue or avoided downtime), because edge programs often have real economic penalties when a site slips.
Inputs you can swap
Input | Symbol | Example range (illustrative) |
|---|---|---|
Months earlier to first IT load (modular vs stick-built) | Δt | 1–6 months |
Monthly value of being live (revenue or avoided downtime) | V | $25k–$250k / month |
Incremental CAPEX (modular premium or savings) | ΔCAPEX | -10% to +10% |
Annual OPEX difference (energy + maintenance + staffing) | ΔOPEX | -10% to +10% |
Discount rate (optional) | r | 6–10% |
Payback logic (simplified)
If modular gets you live Δt months earlier, the “speed value” component is:
Speed value = Δt × V
A simple first-pass payback approximation (ignoring discounting) is:
Payback (months) ≈ (ΔCAPEX − (Δt × V) + 12×ΔOPEX) ÷ V
If that formula feels odd, treat it as a prompt to build a small spreadsheet where each term is visible.
Pro Tip: If your organization struggles to quantify V, don’t force a fake number. Use a scenario table (low/medium/high) and let stakeholders decide which scenario is credible.
Example scenario table (not a claim)
Scenario | Δt (months earlier) | V (monthly value) | Outcome intuition |
|---|---|---|---|
Conservative | 1 | $25k | Speed helps, but payback depends more on CAPEX/OPEX deltas |
Moderate | 3 | $100k | Speed value becomes material; schedule certainty starts to matter |
Aggressive | 6 | $250k | Speed dominates; reliability and uptime proof becomes critical |
Upgrade paths: capacity growth vs density growth
Many teams say “we need an upgrade path” when they actually mean one of two different things:
Capacity growth (more kW/MW, more sites, more modules)
Density growth (more kW per rack inside the same footprint)
A clean comparison should evaluate both.
Modular upgrade paths (common strengths and constraints)
Strengths
Repeatable expansion units can reduce redesign effort.
Standardized interfaces can simplify multi-site rollouts.
Constraints to plan for
Interface discipline is everything: power, cooling, controls, security, and networking must be designed as “plug-compatible.”
Density upgrades can force changes in cooling architecture (air → enhanced air/containment → rear-door or liquid), which may not be a drop-in change.
Stick-built upgrade paths (common strengths and constraints)
Strengths
You can optimize for unusual site constraints.
You can engineer bespoke mechanical/electrical growth paths.
Constraints to plan for
Expansions can be disruptive: more trade coordination, more shutdown windows, more change-management risk.
When each site is different, every future upgrade is a new engineering project.
Reliability: metrics are easy to say, hard to evidence
For a neutral comparison, don’t argue about who is “more reliable” in the abstract. Evaluate reliability as a combination of:
Design intent (redundancy, isolation, maintainability)
Execution quality (commissioning, documentation, change control)
Operating model (monitoring, spares, response, runbooks)
A baseline metric set
Metric | Why it matters | How modular vs stick-built tends to differ |
|---|---|---|
Availability target (e.g., Tier-aligned) | Sets redundancy/maintenance expectations | Both can be engineered to a target; evidence matters |
MTTR | In edge sites, restore speed often matters more than rare-failure probability | Standardized parts + monitoring can reduce MTTR if supported |
MTTD (detect time) | You can’t fix what you don’t detect | Monitoring integration and alert hygiene matter |
Single points of failure | Drives “bad day” scenarios | Both can fail here; diagrams reveal the truth |
Human-error rate | A major hidden driver of downtime | Standardization can reduce variability; poor change control can negate it |
For a concise explanation of the difference between FAT and SAT (and why it matters for defect discovery timing), see Kneat’s explanation of FAT vs SAT. In many programs, the practical question is what your factory acceptance test actually covers versus what is deferred to site testing.
Typical failure modes to pressure-test
Power path: wrong interlocks, misconfigured ATS/STS logic, breaker coordination gaps
Cooling: control loop instability, sensor calibration drift, airflow bypass, condensate handling
Controls/monitoring: alarm floods, missing points list, unclear ownership across vendors
Physical security: access control failures in unmanned sites
A good vendor (modular or stick-built) should be able to show commissioning evidence that these failure modes were tested—not just asserted.
Procurement diligence checklist (use this on any vendor)
What to ask for | Why it matters | Red flag |
|---|---|---|
Scope boundary statement (what’s included/excluded) | Prevents TCO surprises | “It depends” with no written boundary |
Single-line diagrams + redundancy narrative | Reveals real fault tolerance | Unclear failover behavior |
FAT summary + SAT/IST plan | Evidence that integration is tested | Testing described as “standard” with no artifacts |
Interface matrix (Modbus/BACnet/SNMP, dry contacts, APIs) | Controls integration drives MTTR | “We can integrate with anything” with no point list |
Spares strategy + response model | Edge MTTR depends on logistics | No clarity on parts ownership or lead times |
Compliance certificates and scope (CE/ISO/etc.) | Required for many bids | Certificates referenced but not verifiable |
Change control / as-built documentation | Prevents drift over time | No as-built handover package |
Where Coolnetpower fits (neutral, public-data only)
If you want a concrete example of what “integrated scope” looks like in a modular/micro approach, Coolnetpower’s public pages describe:
Integrated cabinet / micro data center scope in MetaRack micro data center cabinet solution
Modular data center scope and expansion positioning in MetaRow modular data center solution
Coolnetpower also publishes an evidence-bound discussion of what modular buyers should verify (and what is not always public across vendors) in “Why choose Coolnet modular data centers”. That framing is useful even if you’re evaluating multiple suppliers.
FAQ
Does modular always mean faster ROI?
Not always. Modular can improve ROI when time-to-service has economic value (revenue, avoided downtime, contractual penalties) and when the solution is right-sized rather than overbuilt. If your critical path is utility interconnect and it dominates the schedule, ROI can be less sensitive to the delivery model.
What CAPEX/OPEX and timeline deltas are proven?
Some vendors publish quantitative comparisons; many do not. Treat published white papers as directional unless you can confirm the assumptions match your program. A commonly cited vendor framing is that scalable, prefabricated approaches can reduce TCO by a material percentage under certain growth/utilization assumptions, as stated in Schneider Electric’s TCO analysis of scalable prefabricated data centers.
How does standardization limit customization?
Standardization tends to limit freedom in layout and component selection, but it often improves repeatability and documentation. For distributed rollouts, that trade can be positive—unless your sites have highly variable constraints (noise, footprint, seismic, local code).
What are upgrade paths for density and capacity?
Capacity upgrades are usually easier than density upgrades. Density often changes the cooling architecture and may introduce new monitoring and leak-detection requirements. If density growth is likely, treat “liquid-ready” interfaces and controls integration as first-class requirements.
What are typical failure modes and MTTR considerations?
The most common “edge downtime” stories are less about exotic equipment failures and more about integration gaps: misconfigured power transfer logic, unstable cooling controls, incomplete monitoring point lists, and unclear runbooks. In distributed fleets, MTTR hinges on detection, spares logistics, and who owns the fix.
Next steps
If you want to operationalize this comparison, request a commissioning checklist + interface matrix + spares plan as part of your RFP package, and evaluate modular and stick-built options against the same evidence set.
If helpful, Coolnetpower can be used as a public reference source for modular scope definitions and template ideas via its integrated data center solutions pages.