Rapid edge data center deployment is often sold as an “install in days” story. For <2MW sites, that can be true—for the physical placement step. But SLA-backed go-live depends on things that do not compress just because the IT is pre-integrated.
If you’re accountable for delivery dates, availability targets, and customer SLAs, you need a definition of “fast” that matches your contracts. In practice, the fastest credible deployments come from parallelizing workstreams (factory build + site prep + utility/carrier coordination) and choosing an architecture that minimizes on-site integration risk.
Key Takeaway: The speed limit for <2MW edge sites is often set by utility power interconnection and fiber provisioning, not by how quickly a module can be shipped.
Table of Contents
ToggleDefine “fast” the way your SLA does
Before comparing architectures or quoting schedules, separate three timelines that get conflated in stakeholder updates.
1) Time to place equipment on site
This is the “pad-to-crane” (or “rack-to-floor”) portion: delivery, set, anchoring, and basic mechanical/electrical hookups.
2) Time to pass commissioning and acceptance
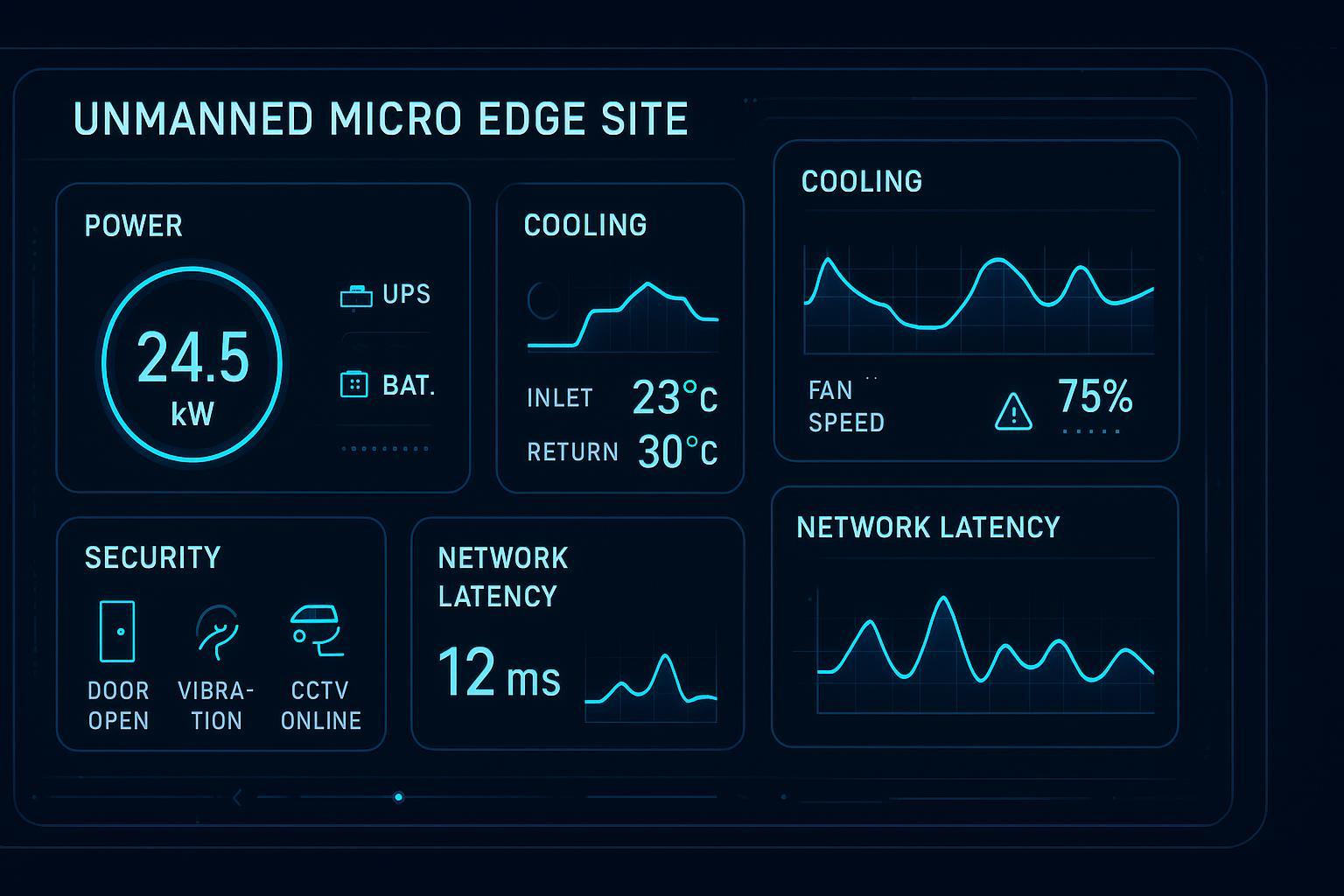
This is where rushed projects lose weeks: controls tuning, alarm verification, power transfer logic, and integrated testing (more on FAT/SAT/IST below).
3) Time to production traffic at required availability and latency
A site that’s physically complete can still be functionally unusable if:
the carrier handoff isn’t live,
routing/DDoS posture isn’t in place,
monitoring/on-call coverage isn’t defined,
or the thermal system isn’t stable under load steps.
SLA risk map: what tends to break first in rushed edge deployments
Edge sites amplify risk because they’re distributed and often lightly staffed. Common first-failure surfaces include:
Power chain: protection coordination, transfer logic, UPS settings, breaker interlocks (electrical installation and safe work practices are often governed by NFPA 70 (NEC) and NFPA 70E in many jurisdictions; see NFPA code pages: https://www.nfpa.org/codes-and-standards/all-codes-and-standards/list-of-codes-and-standards/detail?code=70 and https://www.nfpa.org/codes-and-standards/all-codes-and-standards/list-of-codes-and-standards/detail?code=70E).
Cooling controls: setpoints/alarms and failover behavior under step-load.
Network readiness: incomplete redundancy, brittle configurations, no validated failover.
Physical security: unattended locations and delayed response windows.
A practical starting point is to treat security and physical hardening as non-optional; Data Center Knowledge highlights the physical security challenges of edge environments in its discussion of securing edge data centers.
Timeline benchmarks for rapid edge data center deployment (and what moves them)
There is no single timeline that’s “realistic” for every <2MW edge project because the critical path is frequently outside your direct control. Still, industry sources consistently describe modular/prefabricated approaches as a way to reduce site work and allow parallel workstreams.
Assumptions, scope, and last updated
The benchmarks and risk patterns below are planning guidance, not delivery promises. They assume:
A defined IT load and redundancy target (N/N+1/2N) and a stable reference design.
Site access and permitting are not unusually constrained.
Supply chain conditions are within normal ranges for your region.
Utility and carrier stakeholders will provide firm milestone dates once applications are accepted.
These benchmarks may not apply when grid capacity is highly constrained, new feeders/substation work is required, or fiber requires extensive rights‑of‑way and civil construction.
Last updated: 2026-05-08
As one example of how this is framed in practice, Site Ltd’s discussion of modular delivery notes modular data centers can often be delivered and commissioned in a matter of weeks under the right conditions, in How fast can a modular data centre go live. Treat that as a cited example—not a promise—because it assumes a site and supply chain that support it.
Data Center Knowledge also emphasizes that modular approaches are not universal; they fit specific capacity and use-case patterns, as described in Modular data centers: When they work, and when they don’t.
Diagram: the critical-path timeline (parallel tracks)
Use a critical-path model that makes external dependencies visible early. A simple structure that works well in executive reviews:
Track A (Requirements + reference design): define load, redundancy target, constraints.
Track B (Factory integration + FAT): build and test the module/cabinet off-site.
Track C (Site prep): pad/foundation, conduits, grounding, space readiness.
Track D (Utility interconnection): studies, equipment availability, approvals, metering.
Track E (Fiber provisioning): route design, rights-of-way, construction, turn-up.
Track F (SAT/IST + go-live): on-site integrated testing, handover, operations readiness.
The core schedule advantage of prefabrication is that Tracks B and C can run in parallel. The hard truth is that Tracks D and E can still dominate the calendar.
What “fastest credible” looks like in three <2MW scenarios
Scenario 1: Existing powered space + nearby carrier POP
Fastest path when you can reuse existing electrical capacity and you’re close to an existing fiber presence.
Best fit for rack-scale micro data centers or small modular drops.
Scenario 2: Greenfield pad for a 0.5–2MW site; utility available; fiber needs build
The build itself can move quickly with prefabrication.
Fiber can become the gating item if rights-of-way, trenching, or carrier scheduling slips.
Scenario 3: Utility queue constrained → interim power strategy required
You may be able to stand up compute early, but you must clearly bound what SLA you can underwrite while on interim power.
Table: what actually moves the schedule for <2MW edge sites
Schedule lever | How it helps | Typical failure mode | Practical mitigation |
|---|---|---|---|
Site selection near available capacity | Avoids long utility queue | You discover capacity limits after design | Do a pre-design utility capacity check before ordering |
Standardized one-line + protection scheme | Reduces redesign cycles | Late rework due to AHJ/utility feedback | Reuse a pre-reviewed reference design across sites |
Parallelization (factory build + site prep) | Compresses calendar time | Site isn’t ready when module arrives | Formal “site ready” gate with checklist + owner |
Carrier diversity plan | Prevents latency/SLA surprises | Single path, single POP, no failover | Require dual diverse routes where feasible |
Commissioning evidence pack | Prevents day-30 outages | Controls not tuned; alarms unverified | Define FAT/SAT/IST acceptance criteria in procurement |
Spares + remote hands model | Reduces recovery time | Long MTTR due to access delays | Stock critical spares; contract remote hands; test dispatch |
Utility power is often the schedule killer—treat it like a product requirement
For <2MW sites, the temptation is to treat utility as a background detail. In practice, utility constraints are often the gating factor, especially where grid capacity is tight or equipment lead times are long. For design and audit discussions, many teams anchor requirements and redundancy language to established frameworks such as Uptime Institute Tier guidance (see: https://uptimeinstitute.com/tiers) and ANSI/TIA‑942 ratings (see: https://tiaonline.org/standard/tia-942/ and the certification overview at https://tiaonline.org/products-and-services/tia942certification/).
⚠️ Warning: If utility interconnect is not on a committed schedule, do not treat “module delivery date” as your go-live date.
Why interconnection timelines run long
Common causes include: interconnection studies, transformer/switchgear availability, metering requirements, and limited commissioning/outage windows.
Questions to ask utilities early (RFI list)
Use a structured early RFI to reduce late-cycle surprises:
What feeder/substation capacity is available for the requested load and redundancy posture?
What are the expected lead times for service upgrades and metering?
What are the documentation and inspection gates that must be scheduled?
What outage windows and commissioning constraints should be assumed?
Checklist: utility interconnection artifacts to request early
Artifact | Why it matters for schedule | Owner |
|---|---|---|
Single-line diagram + load summary | Utility review starts here | Owner’s engineer |
Interconnection application packet | Starts the clock in many territories | Owner / EPC |
Utility study requirements and timeline | Avoids “unknown queue” risk | Utility |
Metering requirements | Avoids rework in late stages | Utility |
Commissioning/outage window constraints | Prevents last-minute slips | Utility |
Site access and safety requirements | Avoids rescheduling crews | Utility / EPC |
Design choices that reduce rework and waiting
Standardize voltage and distribution designs across sites where possible.
Stage capacity in increments (design for future modules without redesigning the one-line).
Treat protection coordination and control integration as a commissioning deliverable, not an as-built footnote.
Interim power strategies (when you can’t wait for permanent)
Interim power can be a bridge, but it changes your risk and operating model. If you are interconnecting on-site generation or storage in parallel with the grid (even temporarily), be aware that interconnection and interoperability requirements are commonly governed by standards such as IEEE 1547 (official IEEE SA overview: https://standards.ieee.org/ieee/1547/10906/), alongside local utility rules and AHJ requirements:
Interim power can be a bridge, but it changes your risk and operating model:
Generator-backed interim operations introduce fuel logistics, maintenance scheduling, and operating constraints.
Battery systems can help ride-through and operational stability, but they don’t replace a committed utility path.
The key is to explicitly document what uptime or service commitments are valid during interim mode.
Fiber/carrier readiness: the other “invisible” critical path
Projects often discover too late that network readiness is not just “ordering a circuit.” For edge, time-to-fiber is frequently constrained by rights-of-way, construction scheduling, and turn-up/testing windows.
What drives fiber provisioning lead time
Distance to the nearest POP or meet-me.
Rights-of-way and permitting for digs.
Carrier backlog and subcontractor availability.
Checklist: carrier/fiber questions that protect the critical path
Where is the nearest practical POP, and what is the proposed route (including any third-party easements)?
What is the expected construction scope (aerial vs trench), and who owns the civil work?
What is the lead time for turn-up and test/acceptance, and what are the prerequisites?
What redundancy is available (diverse entry, diverse POP, or only logical redundancy)?
What is the plan for interim connectivity if civil work slips?
Fastest network patterns for edge
For <2MW sites, the patterns that most often reduce schedule and SLA risk:
Dual diverse paths (where feasible).
Early carrier engagement (pre-negotiated master agreements help).
A documented failover plan that’s tested, not assumed.
Interim connectivity options (and their limits)
Microwave/5G/satellite can accelerate early turn-up in some geographies, but they need an explicit workload suitability assessment.
Architecture options that optimize for speed (with tradeoffs)
The fastest deployment is not a single architecture—it’s the architecture that best matches your site constraints and SLA risk tolerance.
Option A: Micro data center (rack/cabinet scale)
When it’s fastest
You already have a ready room, a small footprint, and limited capacity needs.
You want minimum site work and faster repeatability across many locations.
Tradeoffs
Scaling may require more distributed units.
Thermal and serviceability constraints can appear at higher rack densities.
Internal deeper dive: MetaRack micro data center cabinet solution.
Option B: Modular/prefabricated (row modules, skid/container)
Why it can be faster
Integration and pre-testing can happen off-site.
On-site work can be simplified to set, connect, verify, and commission.
Tradeoffs
Logistics and delivery windows matter.
Site constraints (access, crane, pad) can slow what looks “fast” on paper.
Internal deeper dive: MetaRow modular data center solution for scalable infrastructure.
Option C: Hybrid phased deployment (bridge now, harden later)
A pragmatic approach when utility or fiber is the long pole:
Phase 1: minimum viable edge capacity with clearly bounded SLA scope.
Phase 2: transition to permanent utility/fiber and expand in standardized increments.
Option D: “Don’t build”: lease edge-adjacent capacity
In some cases the fastest way to meet near-term compute demand is leasing capacity (edge-adjacent colo or existing facility space) while a permanent build progresses.
Commissioning and acceptance: how fast projects avoid Day-30 outages
Speed without commissioning discipline often shows up as post-handover incidents.
FAT vs SAT vs IST (define and separate)
FAT (Factory Acceptance Test): what must be proven before shipment.
SAT (Site Acceptance Test): what must be proven after installation on site.
IST (Integrated Systems Test): end-to-end behavior under realistic conditions (power events, alarms, failover).
The minimum commissioning evidence set for rapid rollouts
A procurement-friendly way to specify “minimum acceptable proof”:
Evidence item | Why it protects SLA | Typical “fast project” failure this prevents |
|---|---|---|
Power transfer test results (normal → backup → normal) | Proves continuity of service | Hidden transfer logic failures discovered after handover |
Protection/interlock verification | Prevents unsafe or nuisance trips | Late-stage breaker/relay rework |
Thermal step-load stability data | Proves controls are tuned | Hot spots and throttling after tenant turn-up |
Alarm list with verified triggers | Makes monitoring real | Alarms configured but never validated |
Network failover test notes | Proves resilience | “Redundant on paper” links that never fail over |
As-built documentation and owner training | Enables recovery | Extended MTTR due to missing procedures |
Standardization kit for repeatable edge rollouts
The accelerant for multi-site rollouts is not heroics—it’s repeatability:
A golden reference design.
Pre-labeled interconnects.
Commissioning scripts and acceptance templates.
Staffing model for rapid rollout across multiple edge sites
The “two-speed” team structure
Central engineering/standards team sets the reference architecture, acceptance criteria, and change control.
Local deployment crews and qualified partners execute site work and standardized commissioning.
What to standardize to reduce dependency on scarce experts
Reference designs and one-lines.
Controls setpoint baselines and alarm thresholds.
Spare parts strategy and escalation workflows.
Operational readiness for SLA
24/7 monitoring coverage and escalation.
Physical access procedures.
Incident runbooks aligned to SLA language.
Decision framework: pick the fastest path that still clears your risk bar
Diagram: fastest-path decision tree
A decision tree that works well in governance reviews:
Do we have an already-powered site?
Do we have a committed fiber route and turn-up window?
Does the architecture reduce on-site integration?
If interim power/network is required, does the SLA scope explicitly allow it?
Procurement-friendly evaluation table
Option | Speed impact (critical path) | SLA risk profile | CapEx/OpEx direction (typical) | Compliance & auditability | Reversibility |
|---|---|---|---|---|---|
Micro data center (rack/cabinet) | Fast when space/power already exist | Lower construction risk; depends on site security and O&M | Lower initial site work; scaling can add units | Strong if controls/monitoring are standardized | High (can relocate/repurpose) |
Modular/prefab (row/skid/container) | Fast when site is prepared and logistics are straightforward | Integration/commissioning must be disciplined | Higher upfront integration; lower on-site labor | Strong if FAT/SAT evidence is required | Medium (depends on module type/site) |
Hybrid phased (bridge → permanent) | Fastest “compute now” path if utility/fiber lag | SLA must be explicitly bounded during interim mode | Interim OpEx can be higher | Requires transparent risk documentation | Medium |
Lease edge-adjacent capacity | Often fastest calendar path | Depends on provider SLA and contract | OpEx-heavy vs build | Strong if provider has proven compliance | High (contractual) |
Evaluate each option across:
Speed impact (critical path)
SLA risk impact (first-failure surfaces)
CapEx/OpEx directionally
Compliance and auditability
Reversibility (relocate/repurpose)
Common misconceptions (and how they create schedule slip)
“Prefab means no permitting.”
“Install in five days = go-live in five days.”
“Network is easy compared to power.”
Next steps (neutral)
If you want to move faster without creating hidden SLA exposure:
Build a critical-path schedule with utility + carrier milestones that are tracked as first-class deliverables.
Lock a reference architecture and an acceptance evidence pack (FAT/SAT/IST expectations) before ordering.
Run a site readiness checklist that explicitly scores power and fiber risk.
For deeper dives into modular and micro options, monitoring, and standardization approaches, explore Coolnetpower resources such as:
FAQ
What is the fastest way to deploy an edge data center?
The fastest credible path is usually the one that (1) shifts integration and testing off-site, (2) parallelizes factory build with site prep, and (3) treats utility and carrier readiness as first-class schedule risks from day one.
What is the difference between a micro data center and a modular data center?
A micro data center is typically a rack/cabinet-scale integrated unit; Vertiv describes the concept in What Is a Micro Data Center?. A modular data center is a larger prefabricated module (skid/container/row) designed to scale by adding modules; IE Corp provides an overview in What Is a Modular Data Center? A Guide.
Why do utility power and fiber dominate the schedule even for <2MW sites?
Because they often require external approvals, construction scheduling, and constrained equipment availability. You can compress on-site installation, but you can’t “parallelize away” an uncommitted interconnection queue or a carrier buildout.
What commissioning tests are non-negotiable for SLA-backed go-live?
At minimum, you need proof of safe power transfer behavior, stable thermal control under realistic load steps, verified alarms/monitoring, and validated network failover behavior.