Legacy halls rarely get a clean-slate liquid cooling rollout. You’re typically working inside live aisles, mixed workloads, and a maintenance model built around air systems.
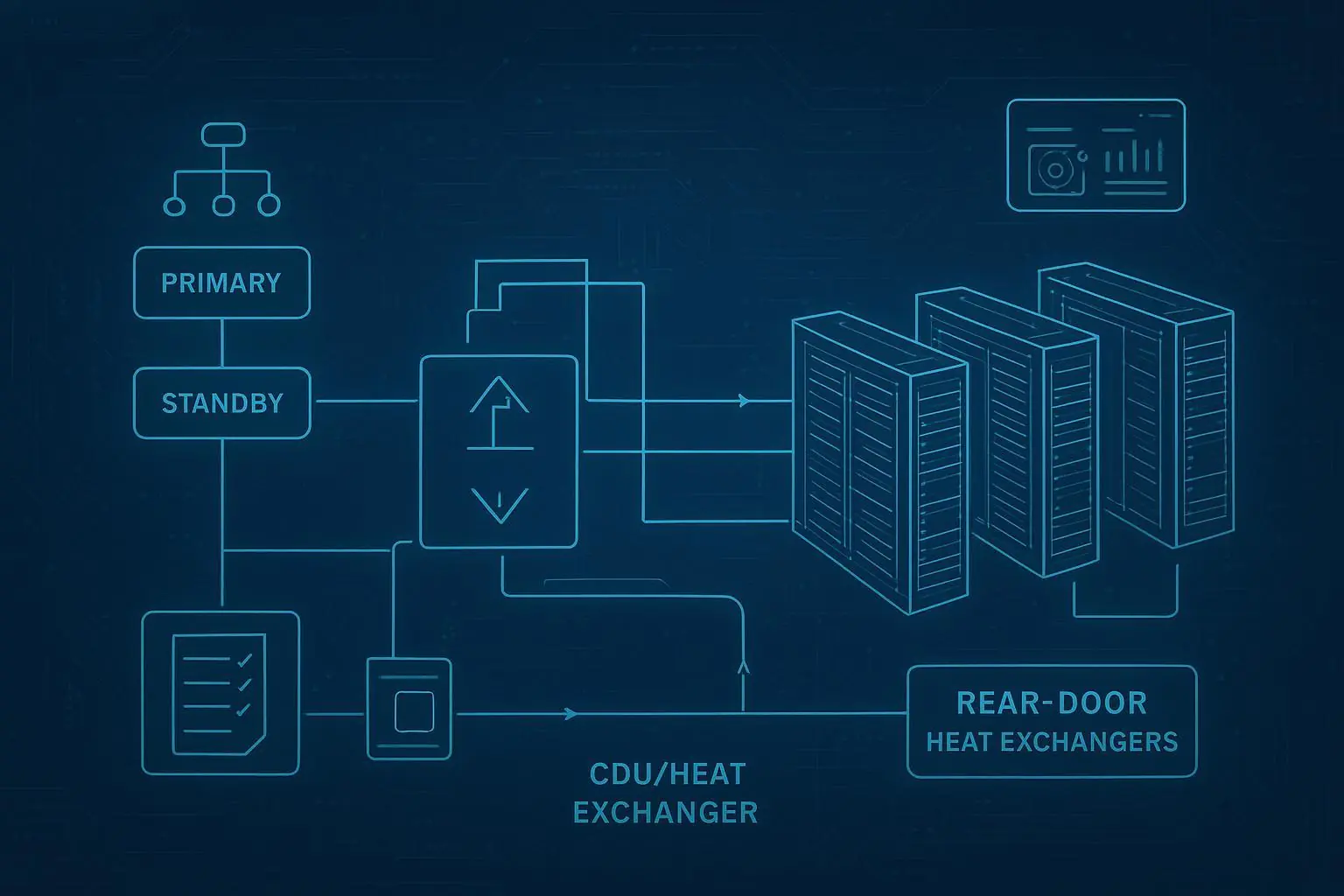
A lower-risk path is hybrid adoption in phases: start with rear door heat exchangers (RDHx) as a rack-level “bridge,” then expand into direct-to-chip (D2C) only where density and workload profiles justify the added plumbing, controls, and operational overhead.
Key Takeaway: A successful hybrid retrofit is less about picking “the best technology,” and more about sequencing, isolation boundaries, commissioning gates, and operational readiness.
Table of Contents
ToggleDefinitions (so everyone uses the same words)
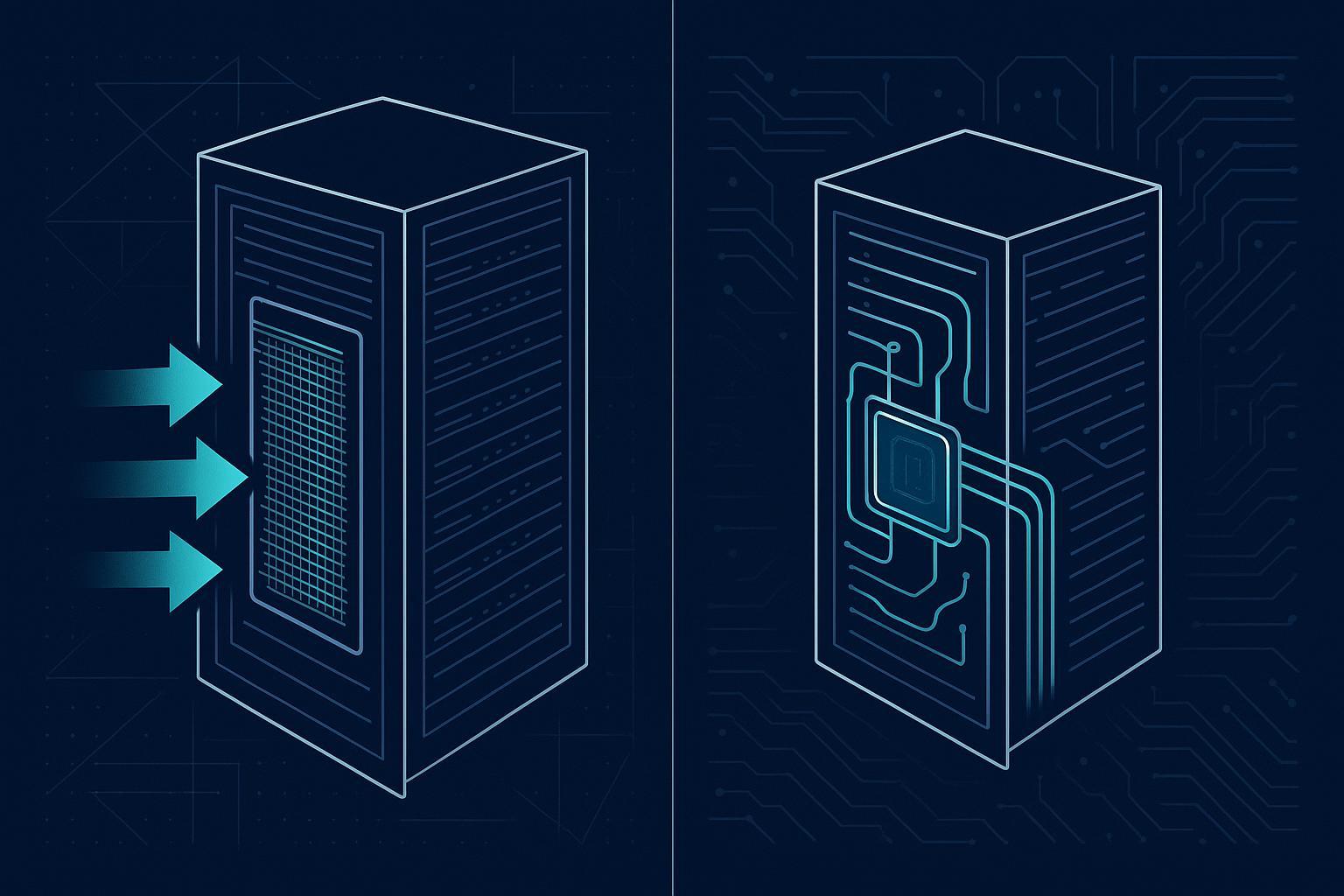
RDHx (rear door heat exchanger): A heat exchanger mounted at the rear of a rack that captures hot exhaust air and transfers that heat to a liquid loop, reducing the burden on room-level air cooling. RDHx is often positioned as retrofit-friendly because it can be deployed rack-by-rack without redesigning the whole hall.
D2C (direct-to-chip liquid cooling): Coolant is routed through cold plates on CPUs/GPUs (and sometimes other components), then through a heat exchanger, to remove heat close to the source. It is highly effective—but introduces new failure modes and operating requirements, including explicit leak risk, which the implementation must control. (See Supermicro’s definition of Direct-to-Chip Liquid Cooling (2024).)
Retrofit principles that minimize “blast radius” (hybrid air–liquid retrofit strategy)
These principles apply no matter which vendor you use.
Best practice 1: Design isolation boundaries before you design pipe routes
Why it matters: In a live hall, the question is not “can we cool it?” but “what happens when something goes wrong at 2 a.m.?”
How to implement:
Define zones (by row, pod, or service corridor) with clear isolation points.
Treat every zone as a unit with its own monitoring, shutoff, and maintenance window.
Plan where you can isolate without draining or disrupting adjacent zones.
Failure mode: A small leak or maintenance event forces a wide outage because the system can’t be segmented cleanly.
Example: A row-level RDHx rollout becomes manageable when each row has accessible isolation valves and alarms tied into operations.
Best practice 2: Make serviceability a requirement, not a nice-to-have
Why it matters: RDHx and D2C add connection points. Connection points are where you will spend your time.
How to implement:
Confirm rear clearance and maintenance access before committing to RDHx locations.
Prefer layouts where technicians can disconnect a rack without “touching” neighboring racks.
Failure mode: Teams avoid preventive maintenance because access is painful—then small issues turn into large incidents.
Example: Several RDHx retrofit discussions emphasize that maintenance discipline (including water-quality and fitting checks) should be treated similarly to established CRAH/CRAC maintenance expectations. (See Data Center Dynamics: “enter through the rear door” (2024).)
The recommended sequencing: RDHx bridge → enablement → selective D2C
Phase 0 (before hardware): baseline your constraints and set go/no-go gates
Why it matters: If you don’t baseline first, you’ll end up “debugging” the facility after you’ve already put liquid near IT.
How to implement: Create a baseline pack your project team can sign:
Current rack map and predicted densification plan
Existing cooling topology and control limits (setpoints, containment, air management)
Available water-side capacity and where tie-ins are feasible
Change windows, commissioning approach, and rollback plan
EHS constraints (spill response, chemical handling, training plan)
Failure mode: The project slips into continuous exceptions—every rack becomes a one-off.
Example: Treat the first deployment zone like a pilot with explicit acceptance criteria (thermal performance, alarms, SOP readiness), not just a “first install.”
Phase 1: Deploy RDHx as the bridge (fast density relief with low disruption)
RDHx is often a pragmatic first move in a legacy hall because it reduces hot exhaust at the rack while keeping the “air world” largely intact.
Best practice 3: Start with a zonal RDHx rollout unless you have a clear rack-by-rack rationale
Why it matters: A retrofit program typically fails from operational complexity before it fails from physics.
How to implement:
Zonal approach (recommended for most live halls): define a row/pod served by a shared supply/return with clear isolation points.
Rack-by-rack approach (use selectively): when the densest racks are scattered or you must isolate each rack due to tenant constraints.
Failure mode: You manage two cooling paradigms (air + liquid) with inconsistent boundaries, increasing operator burden.
Example: Use a zonal boundary to standardize alarms, maintenance procedures, and commissioning gates for the first wave.
Best practice 4: Treat RDHx as targeted heat removal—don’t assume it replaces room-level cooling
Why it matters: Most legacy halls still rely on room airflow management for remaining components and for mixed loads.
How to implement:
Keep your containment and airflow design intact where possible.
Commission RDHx performance in the context of the hall: verify that the retrofit doesn’t create unexpected recirculation or hot spots.
Failure mode: Removing heat at the rack changes airflow patterns and you discover secondary hot spots after rollout.
Example: Use monitoring and periodic inspection recommendations as part of your operational plan; Legrand’s RDHx overview includes maintenance/monitoring considerations that translate well into retrofit SOPs. (See Legrand RDHx guidance.)
Phase 2: Add enablement (distribution, quick disconnects, and monitoring)
This is where many projects either become easy to scale—or become fragile.
Best practice 5: Use quick-disconnects deliberately (and standardize them)
Why it matters: Quick-disconnects are about repeatable maintenance and controlled isolation, not just convenience.
How to implement:
Standardize connection interfaces within a zone.
Place leak detection at high-risk points: connection interfaces and low points.
Document “disconnect / reconnect” steps as part of the rack maintenance SOP.
Failure mode: Inconsistent fittings and undocumented steps lead to human error and extended change windows.
Example: RDHx sources commonly recommend quick-disconnect and leak sensor placement at connections because serviceability is continuous, not one-time.
Best practice 6: Design manifolds and bypass/isolation to avoid draining the world
Why it matters: Retrofits must tolerate service events.
How to implement:
Include isolation valves and bypass capability so you can:
isolate a rack/branch,
keep the zone online,
and restore service without wide draining/refilling.
Failure mode: A minor maintenance task requires draining and refilling a large loop, increasing downtime and water-quality variability.
Example: For D2C, in-rack manifolds are a common pattern for orderly distribution to cold plates—use the same philosophy (clear isolation, controlled connection points) even in RDHx phases.
Best practice 7: Make monitoring “central” from day one
Why it matters: Liquid introduces additional variables—flow, differential pressure, return temperatures, alarms—that operators must see alongside thermal data.
How to implement:
Integrate critical alarms into BMS/DCIM workflows.
Define alarm response playbooks with clear ownership (facilities vs IT vs vendor).
Failure mode: Alarms exist, but don’t reach the right team in time—or they are ignored due to noise.
Example: RDHx discussions often highlight sensors and remote monitoring as part of maintainability; operational value comes when they feed the same monitoring and ticketing flow your team already uses.
Phase 3: Introduce D2C selectively (only when you’re operationally ready)
D2C is not just “more cooling.” It changes maintenance, spares, and response procedures.
Readiness checklist: when you should (and shouldn’t) move to D2C
Readiness question | If “No” | Why it matters |
|---|---|---|
Do you have defined isolation boundaries and a tested leak response SOP? | Delay D2C | Leak risk is explicitly called out in D2C definitions and must be controlled operationally, not just by component choice. (See Supermicro’s definition of Direct-to-Chip Liquid Cooling from 2024.) |
Do you have an established water quality program with routine monitoring and filtration maintenance? | Fix water program first | Fouling/corrosion/microbiology issues are long-tail reliability risks and are harder to fix after scale. |
Can operations support dual systems (air + liquid) without ambiguity? | Keep the footprint small | Running mixed systems adds complexity; plan the transition boundaries carefully. |
Do you have commissioning gates and rollback steps for each zone/rack? | Stop and define gates | Commissioning is how you prevent “unknown unknowns” from going live. |
Best practice 8: Assume hybrid remains necessary (not everything becomes liquid)
Why it matters: Even with D2C, you may still have components and adjacent racks that depend on airflow management.
How to implement:
Keep airflow management in scope (containment, blanking panels, cable management).
Define what is cooled by liquid vs what remains air-cooled in each deployment wave.
Failure mode: Teams assume D2C “solves the hall,” then discover new hot spots or under-cooled components.
Example: Use an explicit “what remains air-cooled” line item in each rack’s commissioning record.
Water treatment and filtration: a practical program for retrofit loops
Water-side reliability is not optional; it determines long-term performance and reduces unplanned maintenance.
Best practice 9: Treat water quality as a controlled operating program
Why it matters: Chemistry drift, particulates, and microbiology can degrade heat transfer and create reliability issues over time.
How to implement: Set a water-quality program that includes:
A monitoring set (at minimum): pH, conductivity, ORP, and relevant chemical concentrations
Defined filter strategy (including side-stream filtration where appropriate)
Startup flushing/cleaning and documented commissioning chemistry targets
(See Consulting-Specifying Engineer’s overview of water treatment best practices for data center cooling (2025).)
Failure mode: You chase “mystery performance loss” that is actually fouling, corrosion, or deposition.
Example: Add filter inspection/replacement tasks to the same CMMS cadence as other critical cooling maintenance.
Best practice 10: Don’t separate filtration from maintainability
Why it matters: A perfect treatment design that is hard to service becomes a deferred maintenance problem.
How to implement:
Place filters where they can be serviced without risky workarounds.
Keep spares and replacement procedures documented.
Failure mode: Filters are bypassed or changed late, increasing particulates and downstream issues.
Example: During early retrofit waves, keep filtration simple, accessible, and standardized per zone.
EHS and training: what “operational readiness” looks like in practice
Best practice 11: Define roles and run drills before scale
Why it matters: In a mixed cooling environment, incident response must be unambiguous.
How to implement:
Define who owns:
isolation decisions,
spill response,
communications to IT/tenants,
and post-incident validation.
Train staff on:
normal operations and alarm response,
safe disconnect/reconnect,
and the steps to isolate a zone.
Failure mode: A minor leak becomes a major outage due to delayed isolation or uncertain ownership.
Example: Pair training with written SOPs and scheduled inspections; operators emphasize that training and procedures are part of successful adoption, not an afterthought.
⚠️ Warning: If your team can’t confidently answer “what do we do in the first 5 minutes of a leak alarm?”, you’re not ready to scale D2C.
A neutral retrofit playbook (quick reference)
Decision matrix: zonal vs rack-by-rack
Decision factor | Zonal deployment (row/pod) | Rack-by-rack deployment |
|---|---|---|
Primary goal | Standardize operations and reduce complexity | Isolate risk by rack; handle scattered hotspots |
Best when | You can group high-density loads physically | High-density racks are dispersed or tenant-constrained |
Commissioning workload | Moderate (repeatable gates per zone) | Higher (unique acceptance per rack) |
Operations | Clear zone-level SOPs and spares | More granular SOPs; more frequent interventions |
Risk profile | Lower complexity; broader shared dependencies | Smaller blast radius; more connection points |
Retrofit checklist (minimum viable controls)
Zone boundaries defined, with isolation points and documented rollback steps
Monitoring integrated (thermal + water-side alarms) with clear on-call ownership
Quick-disconnect standard selected; disconnect/reconnect SOP drafted and trained
Leak detection placed at highest-risk points (connections, low points, manifolds)
Commissioning gate checklist created (pressure/leak checks, flow verification, alarm verification)
Water program defined (monitoring parameters, filtration plan, startup flush/clean)
EHS plan validated (spill response steps, PPE, training frequency, incident reporting)
Where Coolnetpower fits (one example, not a requirement)
If you’re starting with the “RDHx bridge” phase, a rack-level RDHx can be one of the more retrofit-friendly tools to relieve density pressure while you mature the liquid program.
For reference, here’s an example product page for a rear door approach: Coolnetpower rear door heat exchanger.
Next steps
If you’d like, I can convert the checklist above into a commissioning gate template (RDHx wave → zonal enablement → selective D2C), formatted for procurement and site acceptance.
CTA: Request the “Hybrid RDHx→D2C Retrofit Readiness Checklist” and a short technical fit call to adapt it to your hall constraints.