Edge sites force an uncomfortable trade: you need more kW per rack, but you have less space, less staff, and less tolerance for messy failures. In that context, the question is not “Which cooling technology is best?” It is “Which cooling architecture fails in a way you can live with, while leaving you enough density headroom for the next refresh?”
This comparison focuses on three common paths when a facility water loop is acceptable:
Rear-door heat exchanger (RDHx) at the rack exhaust
Direct-to-chip liquid cooling (cold plates + CDU)
In-row DX (near-coupled refrigerant cooling between racks)
Key Takeaway: For edge sites, the winner is usually the architecture that matches your service model. Density and PUE matter, but MTTR and risk containment decide whether you can run it unmanned.
Table of Contents
ToggleQuick comparison matrix (edge reality, not brochure claims)
Criterion | Rear-door heat exchanger (RDHx) | Direct-to-chip liquid | In-row DX |
|---|---|---|---|
Best fit when… | You need a fast density uplift with minimal IT changes | You need sustained high densities and predictable thermals at the chip | You need near-coupled cooling with familiar service workflows |
Density headroom | Medium to high (often positioned as a bridge to full liquid) | Highest (built for high-TDP CPUs/GPUs) | Medium (depends heavily on containment, unit capacity, and airflow path) |
MTTR profile | Usually good if doors are serviceable and the liquid loop is simple and monitored | Can be good if CDU/manifolds are designed for isolation and swap, but training and procedures matter | Often familiar to facilities teams; MTTR depends on parts access, refrigerant procedures, and redundancy |
Liquid or leak risk | Liquid is contained in the door coil; still requires leak detection and dew-point control | Liquid inside racks and on quick disconnects; needs the strongest leak detection + isolation design | Water loop often avoided, but refrigerant leaks and condensate management become the operational risks |
PUE impact | Often improves by raising water temps and reducing fan/compressor work; boundary dependent | Often strongest upside at high density if heat rejection is efficient | Can beat room cooling when well applied; compressor hours drive outcomes |
Deployment model | Rack-by-rack retrofit friendly | Pod-by-pod adoption; highest workflow change | Pod-by-pod; space planning and service clearances are the constraint |
The decision tree (8 questions that usually settle it)
Treat this as a selection flow. If you can’t answer a question, that’s a design gap to close before you buy hardware.
1) What density do you need to support, now and two refreshes from now?
If you need sustained very high densities (AI/GPU-heavy) and the growth path points well beyond what air can handle, you usually end up on direct-to-chip liquid.
If you need a step up from classic air but you don’t want to touch the server internals yet, RDHx is often the least disruptive path.
If your densities are moderate and mixed, and the team already runs DX service workflows comfortably, in-row DX can be a practical compromise.
If you need a one-sentence definition for specs or internal reviews, Supermicro’s glossary is clear about the core RDHx idea and why the liquid loop doesn’t directly contact electronics: Supermicro’s RDHx glossary definition.
2) How constrained is service access, and who is actually on call?
Edge reality:
If the site is unmanned and you depend on remote triage, your “MTTR” is mostly logistics: alarm quality, isolation design, and swap time once a tech arrives.
If the site has local facilities staff who can safely handle refrigerants but not liquid manifolds, that pushes you toward in-row DX.
If you can standardize procedures and training across sites, direct liquid becomes easier to scale.
3) What failure mode do you prefer: gradual degradation or hard stop?
A useful way to think about MTTR is the shape of a failure:
DX capacity loss can sometimes degrade and still keep you inside IT inlet limits if you have margin and redundancy.
Liquid flow problems can turn into a hard stop faster when thermal margins are tight.
Academic failure-mode work on direct liquid cooling reinforces why instrumentation and procedures matter as much as the cooling method itself: ASME’s 2018 failure analysis of direct liquid cooling systems.
4) Are you prepared to run dew-point control like a first-class control loop?
This is a common blind spot.
RDHx and direct liquid can run “warm water,” but only if you treat condensation prevention as a control requirement.
If you cannot trust humidity sensors, airflow containment, and alarms at edge sites, you will end up operating conservatively and giving up some of the theoretical PUE benefit.
5) What is your liquid-risk posture: prevent, detect, isolate, recover?
“Water risk” is not one question. Break it into four:
Prevent: quality fittings, dripless quick disconnects, correct torque and routing, fluid quality management.
Detect: sensing cable in the right places, point sensors under manifolds, pressure/flow anomaly detection.
Isolate: valves and headers designed so one rack (or one pod) can be isolated without taking down the room.
Recover: documented spill response, spare parts, and a rollback mode.
Two practical starting points for leak detection approaches:
A field-oriented overview of methods like sensing cable vs spot sensors: Valin’s 2024 overview of leak detection for liquid-cooled data centers.
An instrumentation-centric summary of leak, flow, and pressure monitoring patterns: Texas Instruments brief on leak detection, flow, and pressure monitoring.
6) Where is your bottleneck: space, power, or cooling?
Edge sites rarely have only one constraint.
If space is the bottleneck, direct-to-chip can be the cleanest density unlock because it can move a large fraction of heat into a liquid loop without requiring proportionally more airflow.
If power is the bottleneck, compare total site draw including fans, pumps, and compressor hours, then evaluate which architecture gives you the most usable IT kW under your redundancy assumptions.
If cooling is the bottleneck, RDHx can be an efficient bridge because it captures heat at the rack exhaust and can reduce the burden on room air systems.
7) Do you need to keep your current server hardware untouched?
This is often the simplest branch:
If you must avoid server modification (warranty, standardization, mixed hardware), RDHx is typically the first move.
If you can standardize on liquid-ready server configurations and have a process for cold-plate service, direct-to-chip becomes realistic.
8) What is the next upgrade path if density keeps rising?
Try to avoid “dead-end” architectures.
A pragmatic pattern is:
Start with containment and near-coupled air (in-row where it fits)
Add RDHx as a bridge to higher density without rewriting everything
Move the highest-density pods to direct-to-chip when the IT stack and operations are ready
A facility-side perspective on RDHx integration and why it can support high-density racks is outlined here: Vertiv’s 2025 explainer on RDHx for high-density racks.
Operating model: what drives MTTR at edge sites
If you want a decision framework that survives procurement and operations review, write down your operating model first. Cooling architecture choices look very different under each of these realities:
Staffed vs unmanned: Do you have hands on site within 30 minutes, or within 6 hours?
Spares strategy: Do you keep spares on site (fans, pumps, controllers), or do you rely on dispatch?
Alarm ownership: Who acknowledges alarms at 03:00, and what are the first three actions?
Rollback mode: If the preferred cooling path is degraded, can you keep IT online long enough to recover?
This matters because edge failures tend to be operational failures. A design that is efficient on paper can still be a poor fit if the site can’t execute the recovery playbook.
MTTR design principles that apply to all three options
Isolation is not optional: design so a single rack or pod can be isolated without losing the whole room.
A “degraded mode” has to be explicit: define what happens when one component fails (what load you can still carry, and for how long).
Alarm quality beats alarm quantity: edge sites fail when alarms are noisy and teams stop trusting them.
Replaceable units beat repair-in-place: if you can’t swap it quickly, you don’t have an MTTR plan.
Instrumentation minimums (the part people skip, then regret)
Edge cooling becomes manageable when you can answer three questions remotely: Is the system moving heat? Is it drifting toward a trip? If it trips, what do I isolate?
Here is a practical minimum set of signals to ask for in design reviews:
RDHx: supply/return water temperature per loop, differential pressure, flow per rack or per branch, door fan status (active RDHx), room dew point (or humidity + temperature), and a leak detection zone map.
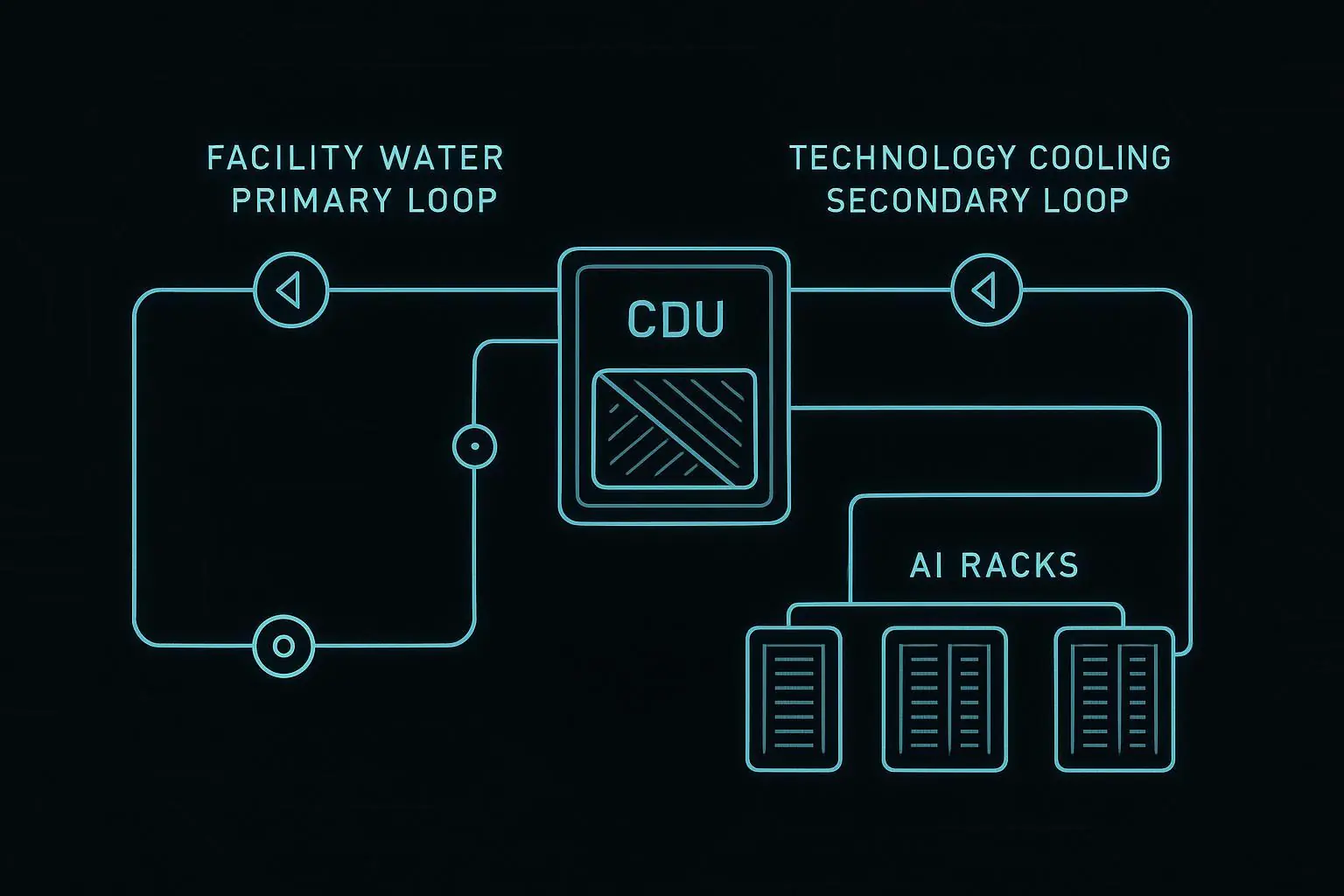
Direct-to-chip liquid: CDU pump status and redundancy state, supply/return temperature, pressure and flow per manifold, and leak detection at the highest-risk joints.
In-row DX: compressor status, supply air temperature, return air temperature, fan status, condensate alarms, and a clear mapping of which unit supports which racks in each redundancy state.
Edge data center cooling architecture: how to compare the four decision drivers
Before you debate vendors, lock the operational assumptions. Edge cooling decisions go sideways when teams compare a “best case” design in one column to a constrained site in another.
Here is the minimum set of assumptions you should write down for any comparison:
Rack power profile: steady-state kW vs burst kW (and for how many minutes)
Allowable inlet temperature band: what the IT hardware actually tolerates
Redundancy state: N, N+1, 2N, and what “degraded mode” means operationally
Service model: staffed vs unmanned, and what your dispatch SLA looks like
Heat rejection method: dry cooler vs evaporative vs hybrid (this drives WUE and parts of PUE)
If you need an internal baseline for how rear-door heat exchangers can affect PUE, with explicit cautions about metering boundaries and boundary conditions, this FAQ is a good reference point: Coolnetpower’s RDHx PUE FAQ (2026).
1) Density headroom (sustained, not peak)
Density comparisons turn into nonsense if you don’t define “sustained” and “supported.” Define:
the rack power profile (steady vs bursty)
acceptable inlet temperature band
redundancy state (N, N+1, 2N)
containment quality
Then ask a vendor to map those assumptions to an acceptance test, not a marketing number.
2) MTTR and serviceability (what breaks, who fixes it, and how fast)
For edge sites, MTTR is rarely about wrench time. It is about whether the system was designed for isolation and swap.
What to check for RDHx
Can a door fan (active RDHx) be serviced without draining the entire loop?
Are there isolation valves and dripless quick disconnects at each rack?
Does your monitoring catch “slow failures” (reduced flow, dirty strainers) before they become temperature alarms?
What to check for direct-to-chip
CDU design: pump redundancy, hot-swap parts, integrated sensors and alarms
Manifold and hose routing: physical protection, strain relief, clear labeling
Maintenance workflow: how you isolate one server, swap a cold plate, purge air, and verify flow
What to check for in-row DX
Redundancy at pod level: can one unit fail while neighbors carry the load?
Refrigerant service workflow: who is certified, what spares are on hand, what the escalation path is
Condensate management and filtration: the boring pieces that drive outages
3) Liquid risk (not just leaks, but consequences)
A reasonable edge posture is: assume a leak will happen somewhere, then design so that it is detected quickly, isolated locally, and recoverable without a full site shutdown.
Where teams get into trouble is treating leak detection as an add-on rather than part of the architecture.
4) PUE impacts (and why PUE can be the wrong north star for edge)
PUE still matters, but edge sites often have small loads where auxiliary power overheads can dominate. Two practical notes:
If your metering boundary is inconsistent, your “PUE improvement” is an accounting artifact.
PUE does not capture outage risk or operational burden.
When you do use PUE as a decision input, require a documented boundary, consistent metering points, and a plan to log across seasons.
Recommendations by edge site type (quick picks)
Factory / warehouse edge
Common constraints: dust, ambient variability, limited HVAC integration, strict uptime expectations tied to production.
Typical pick:
RDHx if you need a meaningful density increase without changing IT hardware and you can run a stable water loop.
In-row DX if your facilities team is strongest on DX workflows and you can preserve service clearances.
Direct-to-chip if you are standardizing on high-density GPU/AI at the edge and can operationalize liquid procedures.
Retail / branch edge
Common constraints: noise, tiny rooms, low tolerance for downtime, minimal on-site staff.
Typical pick:
In-row DX for familiarity and a simpler operational model when densities are moderate.
RDHx if you have clear density pressure and a standardized water-loop module.
Telecom edge
Common constraints: wide ambient ranges, outdoor shelters, remote operations.
Typical pick:
Packaged, monitored systems with strong remote alarming matter more than the cooling type.
RDHx or direct liquid becomes viable when the liquid loop is engineered as a standard module with predictable service steps.
Appendix: Coolnetpower-supported example topologies (optional reference)
This appendix is included to show how the three architectures map to deployable topologies. It is not a performance guarantee.
Example topology A: RDHx as a bridge in mixed-density edge rooms
Pattern: keep room air systems for residual loads and humidity, add RDHx on the densest racks.
Why it’s common: limits disruption and scopes risk to specific racks.
Reference: Coolnetpower’s rear-door vs in-row vs direct-to-chip retrofit comparison (2026).
Example topology B: Direct-to-chip pods for high-density AI edge
Pattern: a dedicated pod with CDU + manifolds feeding cold plates, with containment and strict leak detection.
Portfolio context: Coolnetpower liquid cooling solutions.
Example topology C: Modular edge build where commissioning speed is the product
Pattern: modular systems where power, cooling, and monitoring are delivered as one integrated scope.
References:
Pro Tip: If you cannot standardize alarm thresholds, spares, and isolation procedures across sites, you don’t have a cooling architecture problem. You have an operations design problem.
RFP / acceptance checklist (edge-specific)
Use this as a bid-level checklist. It forces vendors and integrators to be specific about risk containment and service steps.
Area | Question | Pass criteria (example) |
|---|---|---|
Density | What kW/rack is supported under N+1, with stated inlet temp band and containment assumptions? | Assumptions documented; test method defined |
MTTR | What are the top 5 failure modes and the step-by-step recovery playbook? | Clear isolation steps; spares list; who does what |
Leak risk | What leak detection is included (cable/spot), where is it installed, and what’s the alarm workflow? | Detection + isolation + response documented |
Condensation | What dew-point control logic is implemented and what sensors are required? | Dew-point override exists; sensors are specified |
Monitoring | What is monitored (flow, pressure, temps), at what granularity, and where does it alarm? | Rack/pod visibility with actionable alerts |
Commissioning | What is the commissioning scope and acceptance test? | Signed FAT/SAT steps, baseline logging plan |
Metering | If PUE is claimed, what boundary and what metering points are used? | Boundary consistent; method stated |
Next steps
If you want a copy-paste scorecard (weights, scoring rubric, and acceptance-test list) tailored to your edge site constraints, request the “edge cooling decision scorecard + commissioning checklist.”
If you’re leaning toward RDHx or direct-to-chip, a short technical fit call usually settles three things quickly: (1) water temperature envelope vs dew point, (2) isolation and monitoring design, and (3) the realistic MTTR playbook for your staffing model.