Data center discussions about “80–120 kW per rack” usually start as a power conversation—and quickly become a risk conversation: performance throttling, commissioning surprises, water-quality mistakes, and unclear ownership boundaries between IT and facilities.
This FAQ is written for operators planning high-density AI deployments. It focuses on threshold questions you can use to decide when to seriously consider cold-plate liquid cooling (direct-to-chip / DTC), what typically changes in the design, and what to verify before procurement.
Key Takeaway: At 80–120 kW/rack, “Do we need liquid?” is usually already answered. The real question becomes: which liquid architecture, what facility interfaces, and what acceptance criteria keep risk manageable?
Table of Contents
ToggleKey takeaways
There isn’t a universal kW “cliff.” Thresholds depend on rack layout, airflow path, allowable inlet conditions, and how much heat must be removed from CPUs/GPUs versus “everything else.”
For AI/GPU-heavy deployments, industry overviews commonly place direct-to-chip density bands in the tens of kW per rack and upward, with more advanced implementations reaching into ~60–100+ kW/rack ranges depending on architecture.[1]
OEM guidance patterns at high density tend to converge on a few non-negotiables: controlled pressure/flow, clear facility-vs-rack loop demarcation, coolant quality management, and serviceability (isolation valves, quick disconnects, leak detection).
ASHRAE-style guidance is most useful as a framing tool: it helps you set expectations on tighter thermal envelopes for high-density equipment and pushes you to treat liquid cooling as a first-class design path, not an afterthought.[2]
Definitions (quick, practical)
Rack power (kW/rack): Electrical power delivered to IT in one cabinet. Nearly all of it becomes heat.
Direct-to-chip (DTC) cooling: Liquid delivered to cold plates mounted on high-heat components (typically CPUs/GPUs). The rest of the server may still be air-cooled.
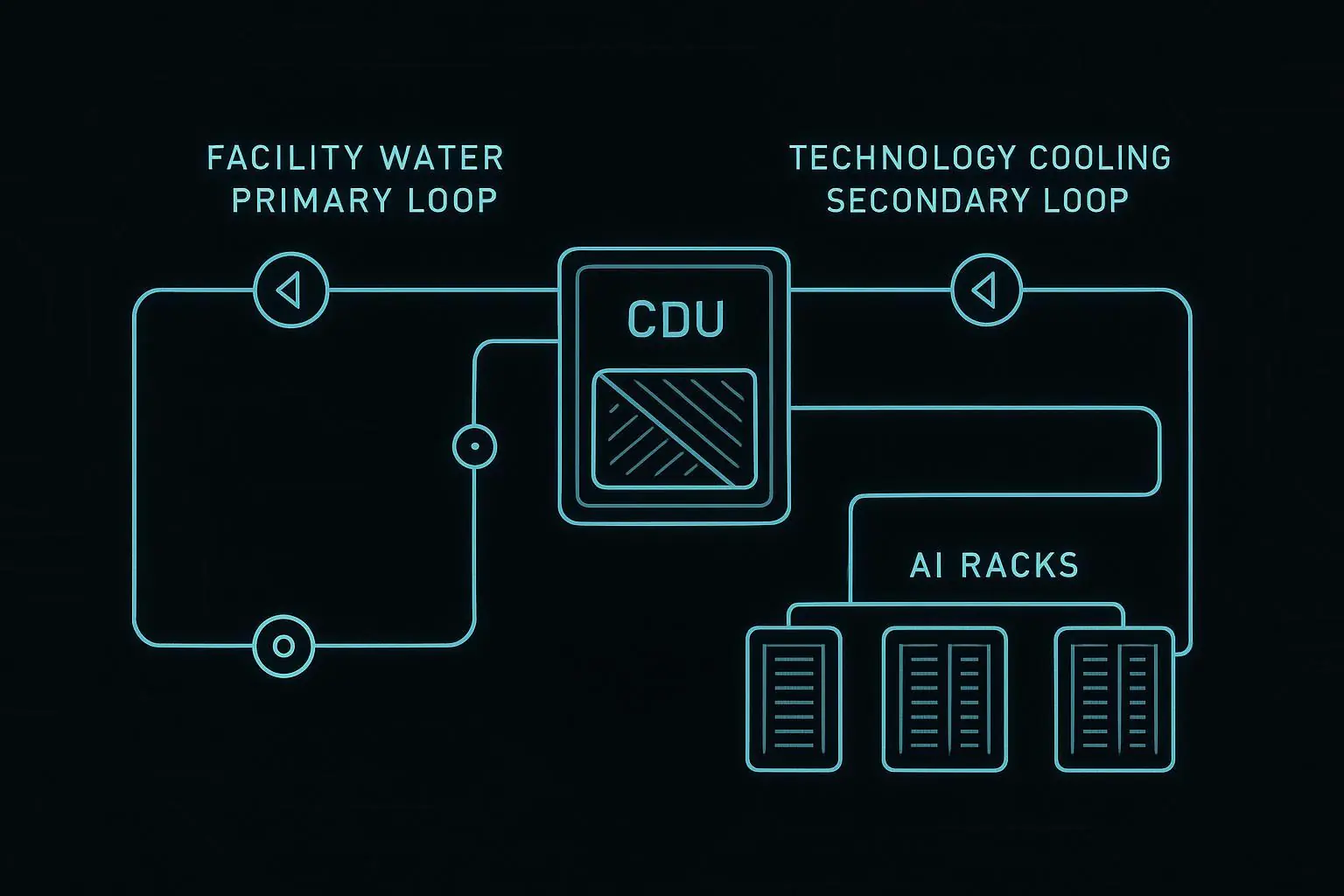
CDU (Coolant Distribution Unit): The rack/pod-level interface that manages flow, pressure, heat exchange, and often isolates the rack loop from facility water.
FWS vs TCS: ASHRAE liquid-cooling guidance commonly describes a demarcation between the Facility Water System (FWS) and the Technology Cooling System (TCS). A CDU is often used to enforce that boundary.[2]
Quick answer: what changes at 80–120 kW/rack?
At 80–120 kW/rack, you’re usually leaving the “optimize airflow harder” phase and entering the “treat the rack like a thermal subsystem” phase.
Typical changes:
Heat is concentrated where air struggles most: GPUs/accelerators and CPUs, with high heat flux and tight junction temperature limits.
Interface ownership becomes a project risk: Who owns coolant chemistry, filtration, pressure/flow alarms, leak response, and maintenance windows?
Redundancy decisions move closer to the rack: Pumps, CDUs, valves, and distribution loops start looking like “critical infrastructure,” not accessories.
Commissioning becomes more like MEP + IT co-validation: You’re validating not only room conditions, but also pressure/flow stability, leak detection behavior, and failover timing.
Threshold questions: “When do we need DTC?”
What rack power levels trigger direct-to-chip consideration?
As a practical rule: you should seriously evaluate DTC when air delivery and heat rejection can’t keep chip temperatures stable under sustained load without aggressive constraints (over-provisioned airflow, tight inlet bands, or unacceptable fan power/noise).
Industry summaries often map single-phase DTC into roughly ~30–60 kW per rack (sometimes higher) and two-phase DTC into ~60–100+ kW ranges, depending on design specifics.[1]
What matters more than the number:
Per-server power and component heat flux (AI nodes behave differently than mixed enterprise racks)
Air path geometry (front-to-back is not a guarantee of “air will work”)
Allowed inlet temperature band and how consistently you can hold it
How much of the rack heat must be captured at the chip (vs “room can take it”)
Does 80–120 kW automatically mean direct-to-chip?
In many AI training deployments, it strongly suggests a liquid-first approach, but DTC isn’t the only liquid architecture.
At 80–120 kW/rack, you typically end up deciding between:
DTC (single-phase or two-phase) for targeted chip heat removal, often paired with a CDU
Hybrid approaches where some racks or components remain air-cooled
Immersion in cases where you want extreme density or a different operational model
The reason it’s not automatic: your “rack kW” could be driven by different realities—e.g., fewer ultra-dense compute racks plus many lower-density support racks, or a pod design where distribution and redundancy choices change the effective limits.
What’s the practical upper limit for air cooling (with containment / RDHx)?
Air cooling is still useful, but in high-density AI environments it usually becomes a supporting role. Even in liquid-cooled deployments, there are still fans, memory, storage, and “everything else” heat loads.
A common industry framing is:
Air cooling: best for lower densities (often cited around ~5–15 kW typical)
RDHx/hybrid: extends viability beyond classic room cooling
Liquid (DTC/immersion): becomes increasingly necessary as density climbs[1]
If you’re already targeting 80–120 kW/rack, it’s worth treating RDHx as either:
a bridge strategy for mixed halls, or
a tool to manage “non-DTC” residual heat in a liquid-forward pod
For readers planning densities below this band, see Coolnetpower’s internal decision resource: RDHx vs direct-to-chip for 30–80 kW racks (decision matrix).
When do OEMs effectively mandate liquid?
OEM advisories vary, but the pattern is consistent: when the hardware’s sustained performance requires tighter thermal control than air can realistically provide at your density, the “recommendation” becomes a design requirement.
In practice, OEM-driven “mandates” usually show up as requirements for:
Defined pressure/flow windows at the server/rack manifold
Clear facility interface (supply/return temperatures, allowable transients)
Coolant quality expectations (materials compatibility, filtration, monitoring)
Validated serviceability (disconnects, isolation, leak response)
You don’t need vendor names to use this: turn it into an RFP question—“Provide the required coolant supply temperature range, pressure/flow limits, and water-quality requirements for sustained full-load operation.”
Facility and design prerequisites (the “what procurement must verify” set)
What additional infrastructure is typically required at 80–120 kW/rack?
Expect to design and procure around these building blocks:
CDU (rack or pod level) to manage pressure/flow and (often) separate facility water from the rack loop
Distribution: rack manifolds, hose kits, valves, dripless quick disconnects
Controls and instrumentation: temperature, pressure, flow, alarms; integration to your monitoring layer
Heat rejection path: tie-in to chilled water, dry coolers, or other rejection method depending on architecture
A practical explainer on CDU types and facility integration is in Vertiv’s 2024 deep dive on direct-to-chip cooling and CDU integration.
What does ASHRAE guidance actually help with here?
ASHRAE is most helpful for two things:
Air-side expectations and “tight bands”: the 2021 update introduced an H1 class for high-density servers, often discussed as requiring tighter air control than general IT guidance—useful context when you’re debating “can we just run it like a normal hall?”[3]
Liquid cooling as a resilience problem, not only an efficiency problem: ASHRAE-oriented guidance emphasizes interfaces, failure modes, and demarcation—especially the need for a clear boundary between facility water and technology cooling loops.[2]
What are typical facility water / coolant requirements (high level, vendor-neutral)?
Treat these as categories to validate, not universal numeric specs (because OEMs will override specifics):
Water chemistry / corrosion control: inhibitors, biocide strategy, compatibility with wetted materials
Filtration strategy: protect microchannels and maintain flow stability
Monitoring: pressure/flow/temperature at minimum; often coolant condition monitoring as well
Operating envelope: supply/return temperatures and allowable transients (including what happens during failover)
⚠️ Warning: At 80–120 kW/rack, “we’ll figure out water quality later” is a reliability risk. Make coolant quality and maintenance responsibilities explicit in scope and contracts.
Who owns what (FWS vs TCS) and why it matters
A recurring failure mode in early liquid deployments is unclear ownership:
Facilities assumes “IT owns the liquid loop.”
IT assumes “facilities water is good enough.”
ASHRAE-focused coverage explicitly calls out CDU demarcation between Facility Water System (FWS) and Technology Cooling System (TCS) to avoid this ambiguity.[2]
Practical ownership questions to assign early:
Who owns coolant sampling, lab testing, and filter changes?
Who owns leak alarms, shutdown logic, and restart procedures?
Who owns the acceptance test: “steady-state at load” and “transient/failover without throttling”?
Examples: how thresholds play out in high-density racks and GPU pods
Example: an 8-rack GPU pod at ~100 kW/rack—what changes vs ~40 kW/rack?
At ~40 kW/rack you may still be deciding between enhanced air/RDHx and partial liquid.
At ~100 kW/rack, the pod typically looks different:
Distribution is engineered like piping, not cabling: isolation valves, maintenance bypass planning, drain/fill procedures.
Redundancy is designed at pod level: N+1 pump capacity, CDU redundancy options, and the ability to isolate a rack without taking down the pod.
Operations and commissioning become first-class: you’ll want clear SOPs for leak events, filter alarms, and maintenance windows.
What redundancy patterns show up most often?
There isn’t one right answer, but common patterns include:
N+1 at the pumping/CDU layer where a single failure shouldn’t force throttling or shutdown
Isolation so a single rack can be serviced without draining the entire pod
Monitoring and alarms that are actionable (not noisy) and integrated with your operational response
What commissioning and acceptance checks are typically required?
For awareness-stage planning, think in terms of the checks you’ll eventually require, even if you don’t have full values yet:
Steady-state validation: rack/pod holds load without throttling across the expected inlet temperature range
Transient response: what happens during pump failover, valve actuation, or power transfer?
Leak detection behavior: detect, isolate, and recover with minimal collateral impact
Water-quality maintenance plan: filters, sampling, alarm thresholds, responsibilities
If you want a technical deep dive before you set these requirements, start with Coolnetpower’s direct-to-chip cold-plate explainer.
Practical checklist: before you sign the PO for 80–120 kW/rack
Use this as a pre-procurement alignment checklist across IT, facilities, and procurement.
Confirm the rack definition: average vs peak kW, and which racks are actually “AI compute.”
Confirm the heat capture split: what % of rack heat must be removed by liquid vs air.
Define the facility interface: supply/return temperature range and allowable transients.
Define the pressure/flow responsibility at the rack manifold.
Specify CDU architecture intent (rack vs pod; liquid-to-liquid vs liquid-to-air) and why.
Decide redundancy targets (N, N+1) and what “no throttling” means in a failure.
Require serviceability: isolation valves, dripless quick disconnects, safe drain/fill.
Define leak detection and response: alarm → isolate → recover procedure.
Define coolant quality program: filtration, chemistry, sampling cadence, ownership.
Plan commissioning: steady-state + transient tests, acceptance criteria, documentation.
Plan operational staffing and training (especially for first deployments).
Confirm the “go-live” constraint: what can be staged vs what must be ready day one.
Calculator Callout: If you’re pressure-testing early assumptions, start with Coolnetpower’s Data Center Cooling & Power Calculator to sanity-check facility power/cooling envelopes before you lock in rack counts and density targets.
Next steps
If you’re still mapping options below this density band, use the earlier-stage comparison: RDHx vs DTC at 30–80 kW/rack.
If you’re already committed to a liquid approach, the fastest way to reduce surprises is to align on CDU sizing inputs (loads, ΔT, redundancy, and operating envelope). Here’s a practical resource: Coolnetpower’s step-by-step guide to CDU sizing for AI racks.