Direct-to-chip liquid cooling is no longer “experimental” for AI/HPC. What’s hard isn’t the concept—it’s turning it into a repeatable, supportable delivery that survives commissioning, handover, and day-2 operations.
This review is written for global distributors and system integrators who need to deliver liquid-ready AI capacity to end clients with clear scope boundaries, bid-pack artifacts, and a support model that doesn’t collapse the first time a leak alarm fires.
We’ll use “direct-to-chip” and “cold plate liquid cooling” interchangeably in this article, since most buyer conversations blend the two terms. The scope is AI data center liquid cooling for high-density racks where the chip-level heat path becomes the bottleneck.
Table of Contents
ToggleVerdict (BOFU readers)
If you’re deploying high-density AI racks where chip heat flux and fan power are the limiting factors, Coolnetpower is a strong shortlist candidate when you want an integrated, end-to-end delivery model—from reference architecture selection to commissioning checklists and an operations-ready handover.
The key idea: with direct-to-chip, you’re not really buying “cold plates.” You’re buying a controlled liquid loop (distribution + controls + service workflow) that must be engineered and verified as a system.
Who this is for (and who it isn’t)
Best fit
Coolnetpower is a good fit when you (or your end client) need:
A partner who can align IT cooling scope + facility interface early (technology loop vs facility loop).
A delivery model that includes commissioning artifacts (acceptance criteria, ramp tests, alarm checks).
A plan for SLAs, spares, and operator training as part of de-risking day-2 operations.
Not the best fit
This is likely not the best match if your buying gate requires:
Published, guaranteed availability metrics (e.g., specific uptime %) and named reference customers, and you cannot accept verification-by-test instead.
A pure “component-only quote” with no expectation of integration or commissioning accountability.
Direct-to-chip liquid cooling reference architectures (and what changes at each scale)
The baseline heat path and interfaces
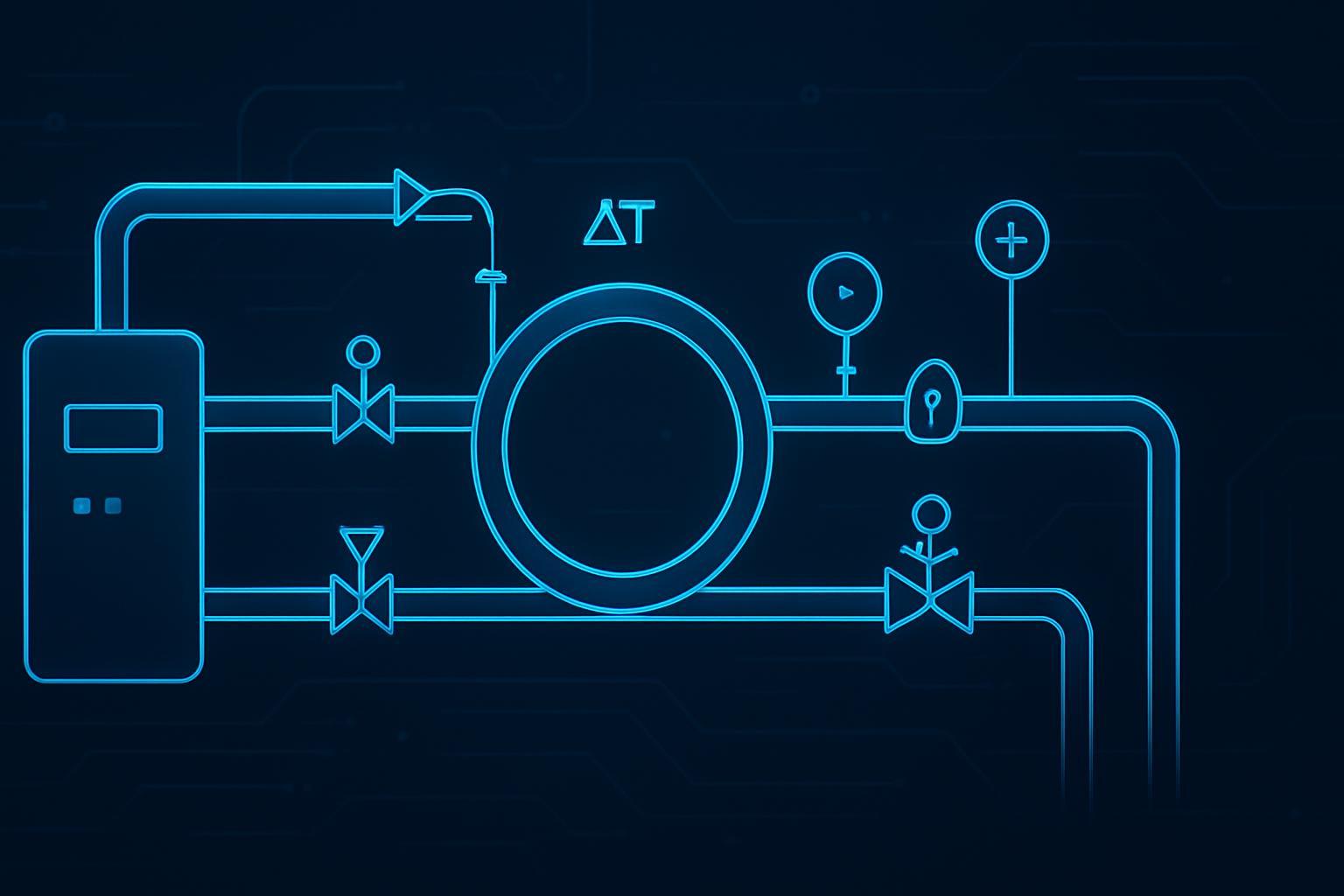
In a standard direct-to-chip architecture, the heat path is:
chip → cold plate → manifold → CDU → facility loop → heat rejection
Coolnetpower’s own overview, Coolnetpower: Direct-to-chip liquid cooling with cold plates explained, breaks this into the core building blocks:
Cold plates at the chip (CPU/GPU).
Rack manifolds that distribute supply/return and support isolation.
A coolant distribution unit (CDU) that pumps the technology loop, monitors flow/pressure/temperature, manages alarms, and uses a heat exchanger to interface with the facility loop.
A facility-side loop (often warm-water) that rejects or reuses heat.
Key Takeaway: D2C is a system. Most project risk lives in distribution, controls, and service workflow—not in the definition of a cold plate.
Architecture A — In-rack CDU (single racks / small pods)
When it makes sense: edge sites, pilots, or small deployments where you want to keep failure domains small and standardize quickly.
What changes:
More units to maintain (more “things” per rack), but outages may stay localized.
Service workflow happens “inside the rack,” so cable management, access, and maintenance steps need to be disciplined.
What to verify:
Isolation and drain/refill procedure does not create a long service outage.
Leak detection and alarm routing are integrated into the site’s workflow.
Architecture B — Row-level CDU (common 8–16 rack pods)
When it makes sense: repeatable pods where you want consistent performance and fewer CDUs to manage.
What changes:
Plumbing and balancing become more central.
The failure domain expands—so redundancy and bypass/service strategy matter more.
What to standardize in a partner delivery:
Manifold strategy and branch balancing.
Instrumentation for flow/pressure/temperature.
Alarm philosophy (when to notify vs when to isolate).
Architecture C — Pod/room CDU (large AI blocks)
When it makes sense: larger buildouts where centralized controls and higher capacities are justified.
What changes:
Operational maturity requirements rise (monitoring, maintenance routines, spares discipline).
Failure-domain design becomes a first-class architecture decision.
For a neutral taxonomy of these placements (in-rack vs in-row vs facility/gallery), Vertiv’s architecture overview is a useful cross-check: Vertiv: evaluating coolant distribution unit (CDU) architectures.
Density bands and hybrid paths (RDHx as a bridge)
Most real sites don’t jump from 10 kW racks to 100 kW racks overnight. They phase.
A common pattern:
RDHx to extend a mixed hall with minimal IT disruption
D2C in the highest-density AI pods
Coolnetpower summarizes those trade-offs in Coolnetpower’s comparison of direct-to-chip vs immersion vs rear-door heat exchangers.
What to evaluate in a direct-to-chip solution (SI-ready matrix)
Below is a procurement-friendly checklist you can reuse in your bid pack.
Evaluation area | What to ask for | Why it matters |
|---|---|---|
Thermal design | Capacity assumptions (per rack and per pod), inlet setpoints, ΔT targets | Prevents “lab number” designs that fail under real workload ramps |
Hydraulics | Flow per branch, max ΔP, pump redundancy, balancing approach | Hydraulics drives stability and prevents hotspot drift |
Controls | What is monitored (flow/pressure/temp), alarm routing, data retention | Enables auditability and faster root-cause analysis |
Risk controls | Leak detection (direct + indirect), isolation valves, containment, dew-point strategy | The difference between a nuisance event and a downtime event |
Water quality | Coolant spec, filtration plan, sampling frequency, flush/clean schedule | Protects cold plates and HX channels from fouling and corrosion |
Maintainability | QD discipline, hot-swap/bypass options, service windows | Keeps day-2 operations predictable |
Commissioning | FAT/SAT scope, ramp tests, alarm and failover tests | Verifies the system behavior before production |
Support | SLA definitions, spares plan, escalation boundaries | Determines risk transfer after handover |
Training | Operator curriculum + competency checks | Reduces human-factor failure modes |
Reliability and availability: how to talk about it without marketing noise
For liquid cooling, “reliability” isn’t a brochure adjective. It’s a set of controls, redundancy choices, and operational behaviors that show up in logs.
A practical place to start is to define what is measured and reported.
The measurement framework your SLA should report monthly
Even if you don’t publish numbers publicly, your project team should be able to produce a monthly report that includes:
CDU string uptime (definition + measurement window)
Alarm response performance (severity definitions; acknowledge/restore windows)
Leak events (detected, verified, false positives; auto-isolation actions)
Control stability (flow/pressure/temperature staying within set bands)
Water quality compliance (filtration status, sample results, exceptions)
For leak detection best practices (direct vs indirect detection, avoiding false alarms), Vertiv’s operational overview is a useful reference: Vertiv: understanding direct-to-chip cooling in HPC infrastructure. A more detailed discussion of sensor approaches and filtration appears in Data Center Dynamics’ paper Direct liquid cooling system challenges in data centers (PDF).
How to validate reliability before go-live
A direct-to-chip system can look stable at average loads and then fail during transient spikes.
Your commissioning plan should explicitly test:
Ramp loads (worst-case workload step changes)
Alarm propagation and escalation routing
Failover behaviors (e.g., pump failure simulation)
Flow balance and ΔP across branches
Coolnetpower’s commissioning checklist framing in their direct-to-chip cold plate explainer is a useful starting point for defining those acceptance criteria.
SLAs, spares, and escalation: what “support” should mean for liquid cooling
In BOFU buying decisions, “support” isn’t a line item—it’s a risk-transfer mechanism.
A good liquid cooling SLA isn’t just a time-to-respond promise. It’s a set of measurable definitions (uptime, stability bands, and incident handling) that can be audited.
If you need a parallel example of how commercial terms vary by density tier and SLA depth in AI/HPC environments, Coolnetpower’s pricing discussion in AI/HPC hosting revenues with liquid cooling premiums is a useful framework.
A practical SLA structure (what to define in writing)
A useful SLA spec for liquid cooling usually defines:
Incident severity levels (critical / major / minor)
What triggers escalation
What is measured (and how)
Reporting cadence and review rhythm
Spares strategy for distributors & SIs
Your spares plan should be explicit and role-based:
What the SI keeps on hand versus what the vendor supplies
Which parts are “must have” to avoid extended downtime (e.g., pumps, critical sensors, filters, fittings)
RMA workflow and documentation requirements
Field support boundaries (who owns what)
A strong partner delivery clarifies boundaries:
SI scope (integration, commissioning, first-line response)
Vendor scope (engineering support, escalation, parts replacement process)
Facility scope (loop water quality, mechanical plant constraints)
Training programs: de-risking day-2 operations
Most liquid cooling failures are not “mystery physics.” They’re procedural.
Suggested curriculum (modules)
A practical training program for operators and SI field teams should cover:
Fluid handling SOPs (fill, drain, purge)
Quick-disconnect and isolation workflow
Alarm response and isolation drills
Water quality monitoring (what is tested, how often, what triggers action)
Commissioning re-validation (what gets re-tested after changes)
What “trained” means (competency checklist)
For BOFU rigor, define pass/fail competencies:
Can the technician isolate a branch safely?
Can the technician interpret flow/pressure trends and triage alarms?
Can the team execute a controlled drain/refill without contaminating the loop?
Evidence you should request from Coolnetpower (partner-ready bid pack)
If you’re evaluating Coolnetpower (or any D2C vendor), ask for artifacts—not adjectives:
A reference architecture for your density band (rack vs row vs pod)
A requirements template (rack kW, facility loop constraints, monitoring interfaces)
A commissioning checklist and SAT acceptance criteria
A bid pack: BOM + drawings + instrumentation list
A support model summary: escalation path, spares expectations, reporting cadence
If your team needs a density-based roadmap to choose architectures, Coolnetpower’s decision framing in The Ultimate Guide to AI Data Center Cooling can help align stakeholders before vendor comparisons.
Next steps
If you’re planning a liquid-ready AI pod and want to evaluate Coolnetpower quickly:
Request a partner-ready package: ask for a BOM + reference architecture for your rack density band, plus a commissioning checklist and SAT acceptance criteria template.
If you also need to justify the business case, bring your measured baseline inputs and use Coolnetpower’s five-year TCO model for GPU racks (direct-to-chip) as a structured way to document assumptions.